
在 Phi Silica 先前突破性的高效能基础上,微软再次迈出了创新性的一步——为这款领先的本地小语言模型(SLM)引入了基于视觉的多模态能力。通过升级,Windows 端侧 SLM 获得了更强大、更多元的应用潜力。
借助对图像理解的支持,Windows 现已内置可运行在 Copilot+ PC 上 NPU 的多模态 SLM,为多项用户体验及开发者 API 提供了强劲动力。本文将详细剖析 Phi Silica 如何实现多模态功能,并探讨其在无障碍体验与生产力提升等方面的创新应用。
目前适配 Snapdragon 平台,后续将支持 Intel 和 AMD 的 Copilot+ PC。
多模态功能的实现
对图像的深度理解,为大语言模型打通了横跨「图像与文本输入 → 生成精准文本输出」的新路径。
在为 Phi Silica 增加文本处理功能后,关键的挑战是:如何在引入视觉能力的同时,避免再部署独立的视觉 SLM,从而最大限度地节省磁盘空间、内存与算力资源,实现内置系统模型的高效集成。
微软的解决方案充分利用了现有的 Phi Silica 及本地已部署的其他模型,只引入一个 8000 万参数的「小型投影器模块」作为系统开销。通过训练精简的「连通器」来实现多模型协同。这一设计不仅是此次突破的关键,也预示了未来端侧 AI 在多模态能力拓展上的普适方法。
- 微软并没有改变 Phi Silica SLM 的基础权重,而是将经过适配的多模态输入直接输入其嵌入层。适配过程由视觉编码器与小型投影器模块共同完成。
- 在「视觉编码器」方面,复用了业界领先的 Florence 图像编码器,该编码器已广泛应用于Windows Recall(预览版)和增强版 Windows 搜索等功能。
- 「小型多模态投影器模块」则专为视觉嵌入与 Phi Silica 兼容而重新训练,而且视觉编码器部分保持冻结状态,以保证原有能力与稳定性。
- 进一步确保新增多模态组件与已量化的视觉编码器及 Phi Silica 之间的协同一致性与质量表现,让系统只需极小的额外内存,就能为用户带来极佳的体验。
由 Phi Silica 驱动的「图像文本说明」功能,需要与 Click to Do(预览版)、文本重写、摘要等多项 SLM 体验并行,甚至能同时支持用户的自定义 AI 任务。组件高度复用,不但显著降低了训练与上线新功能的成本和时间,也优化了系统加载效率和整体内存占用,为用户带来了更流畅、智能的全新体验。
多模态能力如何提升无障碍体验
让屏幕内容(无论是文本还是图像)变得「可理解」,是计算机无障碍体验进步的关键。
- 目前,包括 Word 和 PowerPoint 在内的多款微软应用都能自动为插图生成「文本说明」(Alt Text)。再配合「讲述人」等屏幕朗读工具,可以帮助视障用户理解屏幕内容。现有的 Alt Text 生成主要依赖于云端大模型,能够快速为图片提供简要的视觉摘要。
- 现在,Phi Silica 的多模态能力极大提升了本地端对屏幕内容的描述能力。无论是简洁的 Alt Text,还是更详尽全面的长描述,Phi Silica 都能灵活生成不同层级的图像解读,让 AI 生成的说明真正贴合用户需求。
本地部署的 Phi Silica 使得高质量的「图像描述」可以即时完成,还无需联网。这不仅进一步提升了无障碍体验,也能更好地服务于视障和低视力人群。
接下来,我们将深入解析 Phi Silica 多模态能力的核心组成,包括如何使用视觉编码器提取图像 Token、如何训练多模态投影器模块,并对系统的整体表现进行评估。
视觉嵌入提取流程
图像视觉嵌入的提取环节
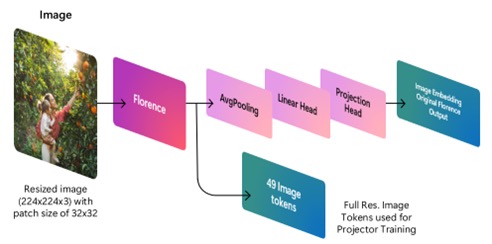
如前所述,在图像视觉嵌入的提取环节,微软采用了 Florence 图像编码器:
- 图像经过 Florence 处理后,会提取出相应的视觉特征,这些特征随后会被输入到多模态投影器模型中。
- 投影器经过训练,其输出的嵌入能够与 Phi Silica 的嵌入空间完美对齐,从而与文本输入一起送入 Phi Silica。
- 投影器的结构非常精简,仅由 2 层线性层串联构成,不仅高效,还大幅减少了新增参数量,使得多模态功能只需新增数百万参数,而无需引入一个动辄数十亿参数的视觉语言模型。
- 为了提升推理效率,微软设计了一种只需对原始图像进行一次裁剪(crop)的机制,区别于其他需要多次裁剪处理的竞品方案,大幅优化了端到端推理流程。
综合来看,每张图片系统仅需处理 49 个视觉 Token,即可实现高效流畅的整体推理。
投影器训练阶段
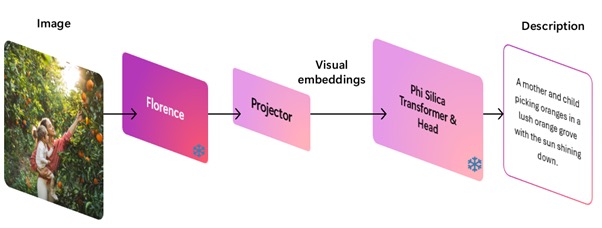
- 在训练投影器时,保持视觉编码器和 Phi Silica 语言模型的权重不变,最大化复用已有基础模型。视觉编码器和 Phi Silica 均以量化形式运行在 NPU 上。
- 为避免量化可能带来的性能损失,训练前专门对量化后的视觉编码器生成图像 Token,并以此构建训练数据集,确保实际部署时表现一致。
- 考虑到端侧设备在内存和延迟方面的严格限制,训练后的 Phi Silica 会通过 QuaRot 工具进行 4-bit 量化,从而高效落地。
- 然而,投影器必须与未旋转的 Phi Silica 保持兼容。为此,对视觉流的嵌入应用相同的随机 Hadamard 变换,使其输出适配后续的推理流程。
为确保文本和视觉嵌入在量化过程中的尺度被准确捕捉,微软还在投影器的输出中引入了一部分校准(calibration)数据,用于泛化量化。该过程只需执行一次,并配合合理的归一化设计,后续训练即可保证输出始终适配量化后的 Phi Silica 模型。
视觉编码器与投影器的联动机制
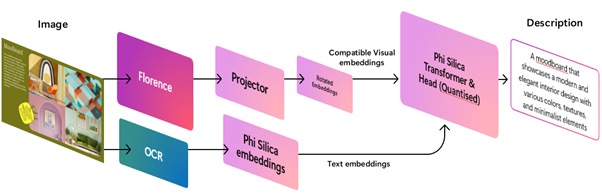
虽然视觉编码器本身已经具备一定的图片文字识别能力,但在遇到像图表、流程图等需要高精度文本提取的场景时,仍可结合 OCR(光学字符识别)模型,实现视觉编码器与投影器的协同运作。
投影器会将视觉信息与 OCR 提取的文字内容进行融合,统一输入到 Phi Silica。这种设计在增强视觉理解能力的同时,也保留了 Phi Silica 原有的文本处理功能,实现更全面的多模态处理。
Phi Silica 多模态图像描述示例
Phi Silica 的多模态图像描述功能,目前已经可以在 Copilot+ PC 上的多种场景中应用:
- 可以自动生成简洁准确的 Alt Text,也能输出详细深入的长文本描述,实现与图片内容的丰富交互。
- 实测数据显示:短描述平均生成时间约为 4 秒,字符数约 135;长描述平均耗时约 7 秒,字符数可达 400~450。(目前主要支持英文,未来会逐步扩展到多语种支持。)
以下是一个 Phi Silica 图像文本说明的实际用例:
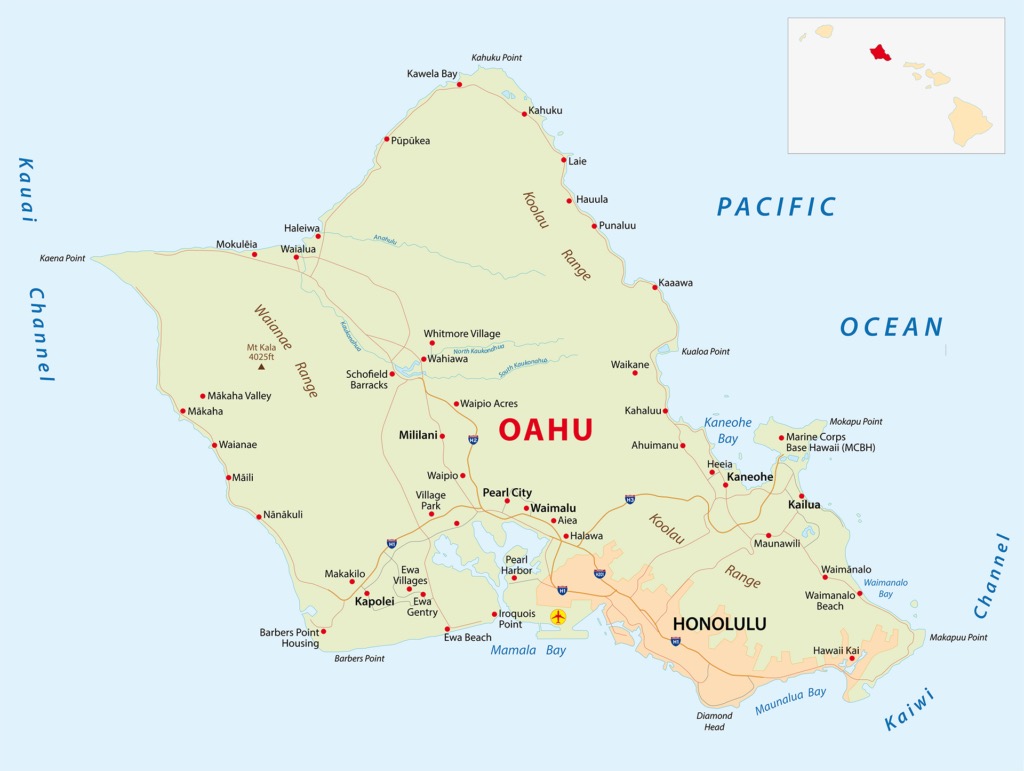
- 当前 Alt Text 示例:
A map of the island
- Phi Silica 多模态短描述示例:
The image depicts a map of the Hawaiian island of Oahu, showing various locations such as Kahuku Point, Kawela Bay, Kahuku and other points and villages, including Pearl City and Ewa Beach.
- Phi Silica 多模态长描述示例(面向无障碍):
The image is a map of the Hawaiian island of Oahu, depicting various locations and geographical features. Key locations include Kahuku Point, Kawela Bay, Kahuku and Kauai. Other notable locations are Laie, Koolau, Hauula, Punaluu, Mokulēia, Anahulu, Waialua, Kaaawa and Kaukonahua. The Pacific Ocean is also visible. Other locations mentioned are Whitmore Village, Mt. Kala, Kualoa Point, Wahiawa and Kaneohe. The image also shows various villages and towns such as Mililani, Ahuimanu, Pearl City and Waipio. Other notable locations include Kahulu, Nānākuli, Koolau and Waimanalo.
系统能力评估
微软以 Florence 基础模型为基准,采用 LLM-as-a-judge 的评估方法,对 Phi Silica 多模态生成的图片描述进行了专业评测。具体评估流程如下:
- 使用 GPT-4o 作为评分模型,根据输入的图片与对应的描述文本,从「准确性」和「完整性」两个维度进行打分,满分为 5 分。
- 测试集涵盖了多种常见图像类型,包括自然摄影、图表、地图、示意图、表格和屏幕截图,确保评估具备广泛的代表性。
通过雷达图直观地对比了以下 3 类图像描述的表现:
- 基于 Florence 的通用短无障碍描述
- Phi Silica 多模态生成的短描述
- Phi Silica 多模态生成的详细描述
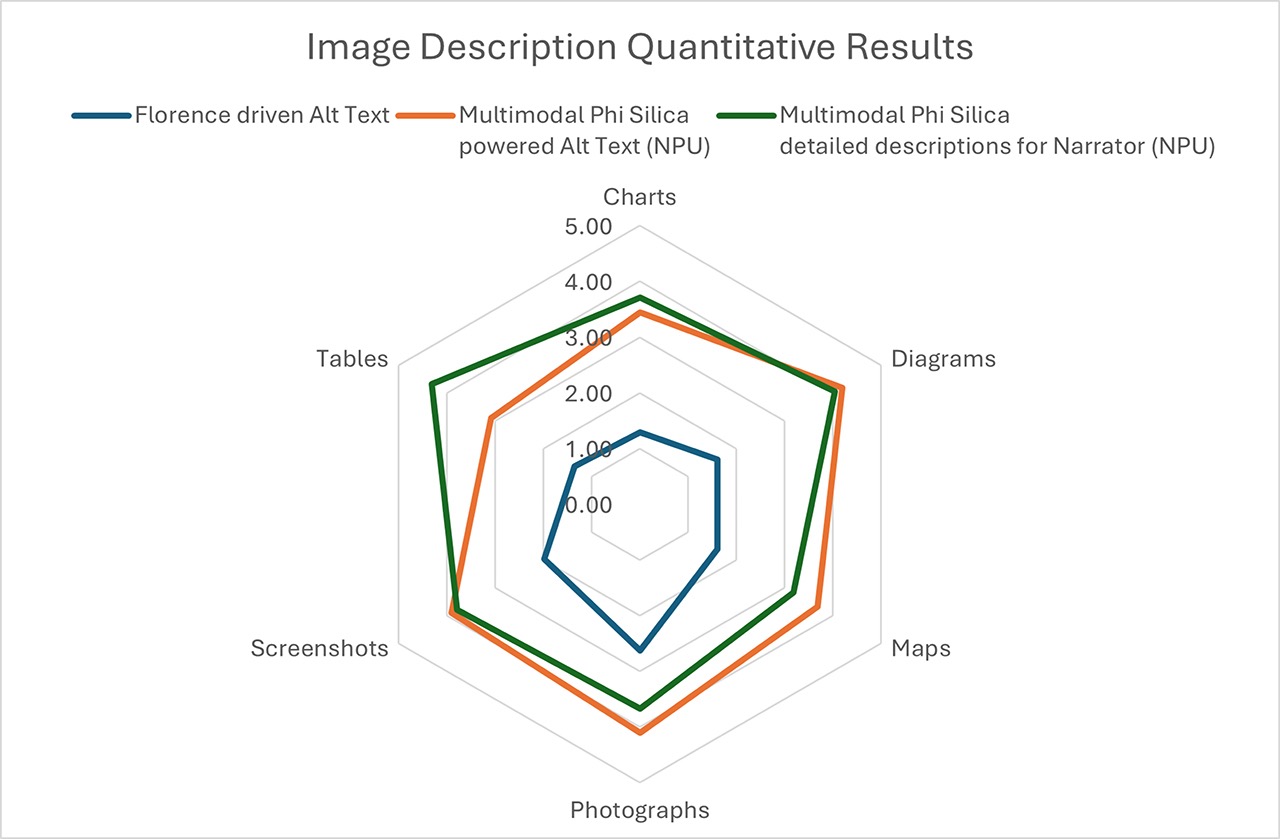
综上所述,基于 NPU 的 Phi Silica 多模态功能,能够在 Windows 端实现本地化的图片描述服务。通过创新性地整合 Florence 视觉编码器与 Phi Silica 语言模型,系统能够高效生成内容详实、语义丰富的屏幕内容描述。
该方案不仅支持短摘要和长说明两种描述模式,还显著提升了 Alt Text 的生成质量,为视障及低视力用户带来了更便捷、更自然的无障碍体验。同时,也充分展现了本地端 AI 在多模态处理方面的强大潜力与应用前景。


最新评论
nb啊成功了,运行的时候会有很多错误代码,可以逐个根据提示关闭某些软件或者打开防火墙就行了。
良心
高质量答案
今日精彩瞬间等小程序添加选项为灰色,不能添加,这个是什么原因?