GLM-5 正式发布!这是一款专为复杂系统工程与长周期 AI 智能体任务而生的大模型。在通往「通用人工智能」(AGI)的道路上,Scaling Law(缩放定律)依然是提升智能效率最核心的驱动力。
- 相比前代 GLM-4.5,GLM-5 将参数规模从 355B(激活 32B)大幅提升到了 744B(激活 40B),预训练数据量也从 23T 激增到了 28.5T Tokens。
- 更重要的是,GLM-5 集成了 DeepSeek 稀疏注意力机制(DSA),在显著降低部署成本的同时,完整保留了处理长上下文的能力。
强化学习(RL)被业界普遍视为填补预训练模型从「合格」到「卓越」之间鸿沟的关键。然而,受限于训练效率,在大语言模型(LLM)上大规模应用 RL 始终是一大挑战。为此,智谱 AI 开发了 slime——一套全新的「异步 RL 基础设施」,大幅提升了训练吞吐量与效率,让更精细的后训练(Post-training)迭代成为可能。
得益于预训练与后训练的双重进化,GLM-5 在推理、编程以及 AI 智能体任务上的表现,不仅全面超越了 GLM-4.7,更在所有开源模型中独占鳌头,性能也已直逼最顶尖的闭源前沿模型。
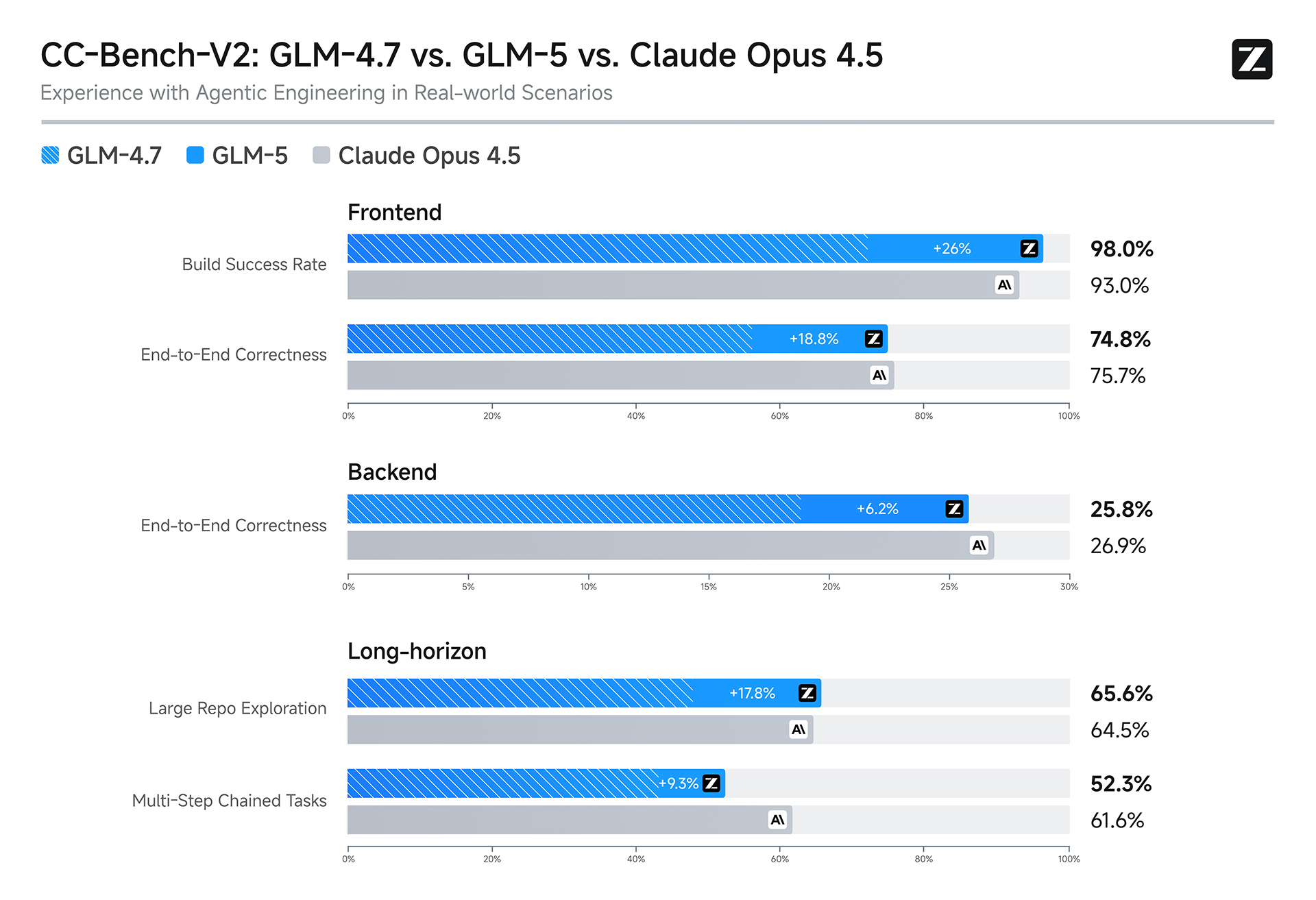
GLM-5 的设计初衷,就是为了解决复杂系统工程与长程任务。在智谱 AI 内部的评测集 CC-Bench-V2 上,无论是前端开发、后端架构还是长周期任务,GLM-5 都大幅领先于 GLM-4.7,并正在快速缩小与 Claude Opus 4.5 之间的差距。
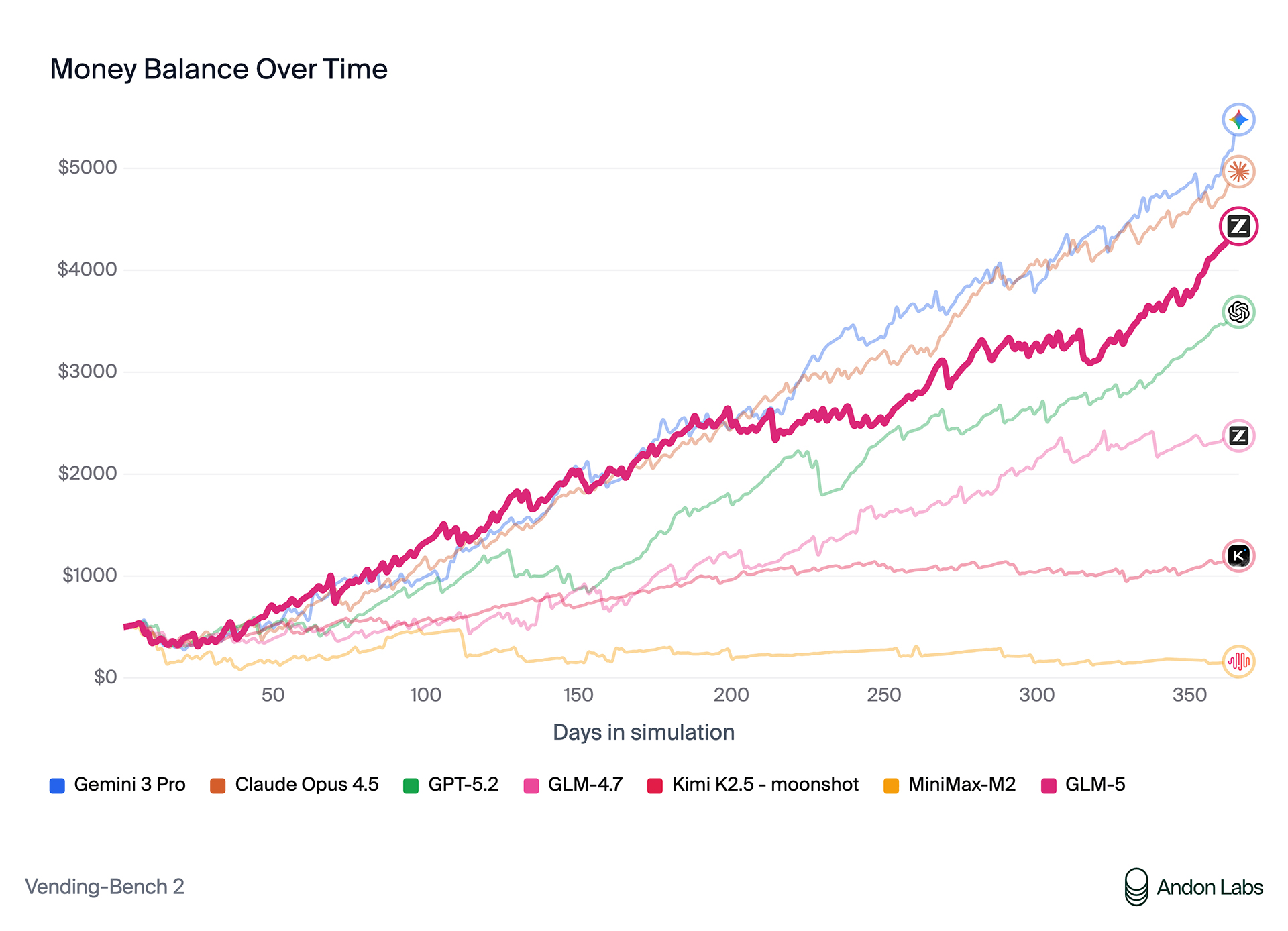
在衡量长期运营能力的 Vending Bench 2 基准测试中,GLM-5 拿下了「开源模型第一」的成绩。该测试要求模型在模拟环境中经营一家自动售货机公司,时间跨度长达一年。GLM-5 最终实现了 4432 美元的账户余额,不仅展示了强大的长期规划与资源管理能力,更已迫近 Claude Opus 4.5 的水平。
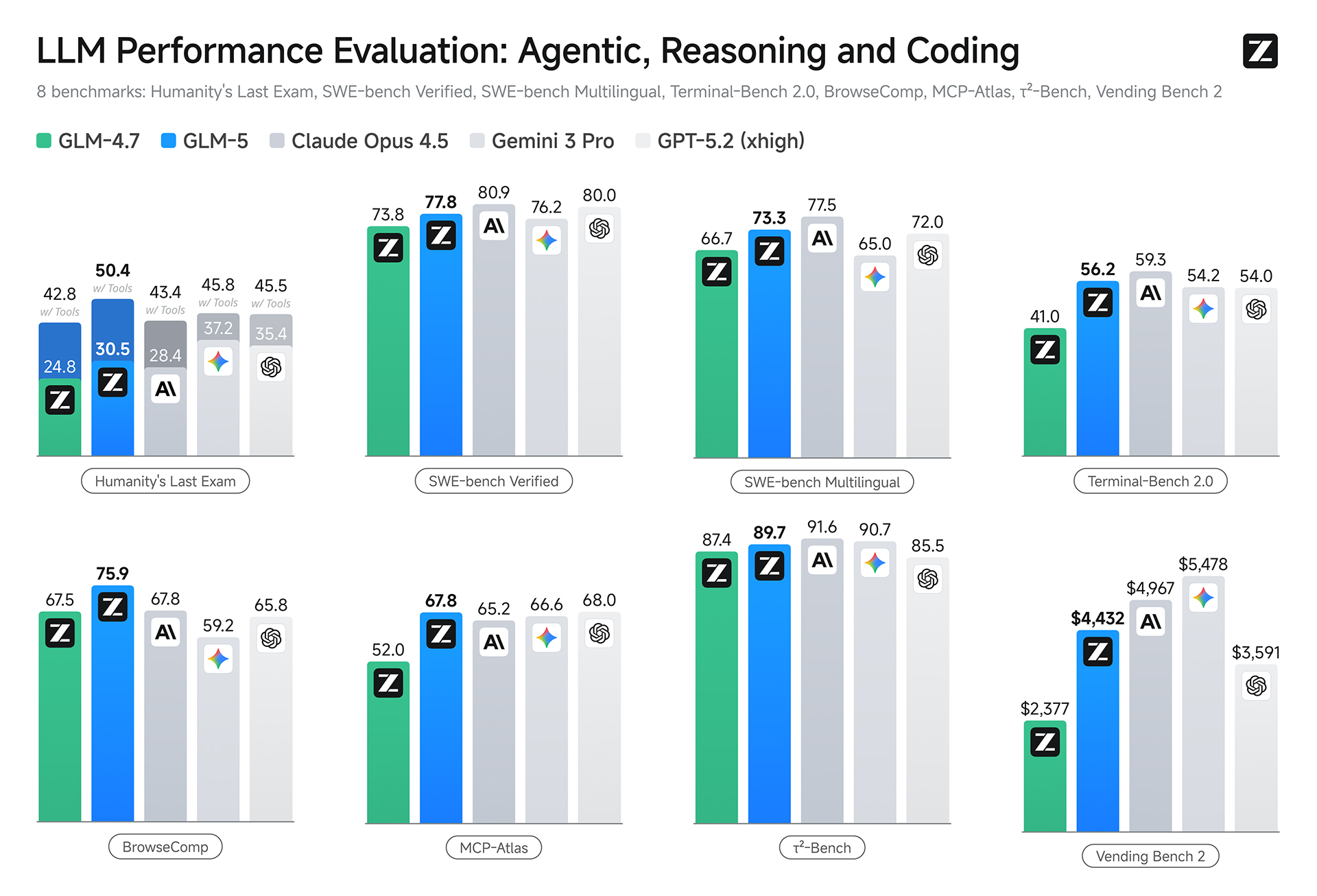
| Benchmark | GLM-5(Thinking) | GLM-4.7(Thinking) | DeepSeek-V3.2(Thinking) | Kimi K2.5(Thinking) | Claude Opus 4.5(Extend Thinking) | Gemini 3.0 Pro(High Thinking Level) | GPT-5.2(xhigh) |
|---|---|---|---|---|---|---|---|
| Reasoning | |||||||
| Humanity’s Last Exam | 30.5 | 24.8 | 25.1 | 31.5 | 28.4 | 37.2 | 35.4 |
| Humanity’s Last Examw/ Tools | 50.4 | 42.8 | 40.8 | 51.8 | 43.4* | 45.8* | 45.5* |
| AIME 2026 I | 92.7 | 92.9 | 92.7 | 92.5 | 93.3 | 90.6 | – |
| HMMT Nov. 2025 | 96.9 | 93.5 | 90.2 | 91.1 | 91.7 | 93.0 | 97.1 |
| IMOAnswerBench | 82.5 | 82.0 | 78.3 | 81.8 | 78.5 | 83.3 | 86.3 |
| GPQA-Diamond | 86.0 | 85.7 | 82.4 | 87.6 | 87.0 | 91.9 | 92.4 |
| Coding | |||||||
| SWE-bench Verified | 77.8 | 73.8 | 73.1 | 76.8 | 80.9 | 76.2 | 80.0 |
| SWE-bench Multilingual | 73.3 | 66.7 | 70.2 | 73.0 | 77.5 | 65.0 | 72.0 |
| Terminal-Bench 2.0Terminus-2 | 56.2 /60.7† | 41.0 | 39.3 | 50.8 | 59.3 | 54.2 | 54.0 |
| Terminal-Bench 2.0Claude Code | 56.2 /61.1† | 32.8 | 46.4 | – | 57.9 | – | – |
| CyberGym | 43.2 | 23.5 | 17.3 | 41.3 | 50.6 | 39.9 | – |
| General Agent | |||||||
| BrowseComp | 62.0 | 52.0 | 51.4 | 60.6 | 37.0 | 37.8 | – |
| BrowseCompw/ Context Manage | 75.9 | 67.5 | 67.6 | 74.9 | 67.8 | 59.2 | 65.8 |
| BrowseComp-Zh | 72.7 | 66.6 | 65.0 | 62.3 | 62.4 | 66.8 | 76.1 |
| τ²-Bench | 89.7 | 87.4 | 85.3 | 80.2 | 91.6 | 90.7 | 85.5 |
| MCP-AtlasPublic Set | 67.8 | 52.0 | 62.2 | 63.8 | 65.2 | 66.6 | 68.0 |
| Tool-Decathlon | 38.0 | 23.8 | 35.2 | 27.8 | 43.5 | 36.4 | 46.3 |
| Vending Bench 2 | $4,432.12 | $2,376.82 | $1,034.00 | $1,198.46 | $4,967.06 | $5,478.16 | $3,591.33 |
办公场景:从聊天进化为实干
基础大模型正在经历一场从 Chat(闲聊)到 Work(工作)的范式转移——就像 Office 之于知识工作者,IDE 之于工程师。
- 如果说 GLM-4.5 是迈向推理、编程和 AI 智能体的第一步,那么 GLM-5 就是在复杂系统与长程任务上的集大成者。
- 它不再止步于文本生成,而是能直接将素材转化为
.docx、.pdf和.xlsx文件——无论是产品需求文档(PRD)、教案、试卷,还是财务报表、流程单、菜单,GLM-5 都能端到端交付「即刻可用」的文档。
官方 Z.ai 已经上线了内置 PDF、Word 和 Excel 创建技能的「Agent 模式」,支持多轮协作,把 AI 的输出真正变成可交付的工作成果。
上手指南:如何使用 GLM-5
在编程环境中使用 GLM-5
你不仅可以在 Claude Code、OpenCode、Kilo Code、Roo Code、Cline 和 Droid 等主流 Coding Agents 中调用 GLM-5,还能借助其强大的工具集成能力完成复杂工程任务。
针对 GLM Coding Plan 订阅用户:
受限于算力资源,智谱 AI 将分批次向 Coding Plan 用户开放 GLM-5:
- Max 计划用户:现在即可启用。只需在配置文件(如 Claude Code 的
~/.claude/settings.json)中将模型名称修改为"GLM-5"。 - 其他计划用户:支持将随推广逐步开放。
- 配额提示:请注意,调用 GLM-5 消耗的配额要高于 GLM-4.7。
配合 OpenClaw 使用
除了编程,GLM-5 还全面支持 OpenClaw 框架。它能变身成你的个人数字助理,跨越 App 与设备边界执行操作,而不仅限于对话框内的问答。
OpenClaw 已包含在 GLM Coding Plan 中。使用指南:点击查看
在 Z.ai 上直接对话
通过 Z.ai 可以直接访问 GLM-5,并提供了 2 种交互模式:
- Chat 模式:即时响应,交互流畅,适合轻量级任务。
- Agent 模式:调用多种工具与技能,直接交付复杂结果。
本地私有化部署
GLM-5 的模型权重已经在 HuggingFace 和 ModelScope 上公开。本地部署支持 vLLM 和 SGLang 等主流推理框架。
另外,GLM-5 现已适配华为昇腾、摩尔线程、寒武纪、昆仑芯、沐曦、燧原、海光等多款非 NVIDIA 芯片。通过底层 Kernel 优化与模型量化技术,GLM-5 在这些国产硬件上均能实现相当可观的推理吞吐量。

最新评论
电脑睡眠后出现灰屏(不亮也不黑),也不能唤醒,是什么原因,如何解决?
淘宝、csdn,这些网站一个个的都想扫描内网是干嘛
还有下载链接,感谢
用这个在线的网站生成也比较合适:https://www.cron.ren