
Google 重磅推出了 Gemini 2.0 系列的首个成员——Gemini 2.0 Flash 实验版。该模型以低延迟和高性能为核心特点,预计将在技术前沿领域得到广泛应用。
作为 Google 迄今为止最强大的 AI 模型,Gemini 2.0 不仅具备原生的多模态能力,能够处理文本、图像、音频等多种数据类型,还新增了多模态输出、图像生成和音频输出等功能。更值得一提的是,它还可以直接调用 Google 搜索和地图等工具,大幅提升了 AI 的实用性。
Gemini 2.0 Flash:性能翻倍,功能更强
Gemini 2.0 Flash 是基于 1.5 Flash 版本的全新升级。新版本不仅延续了快速响应的特点,还在关键基准测试中展现出了比 1.5 Pro 更强的性能,运行速度更是提升了一倍。
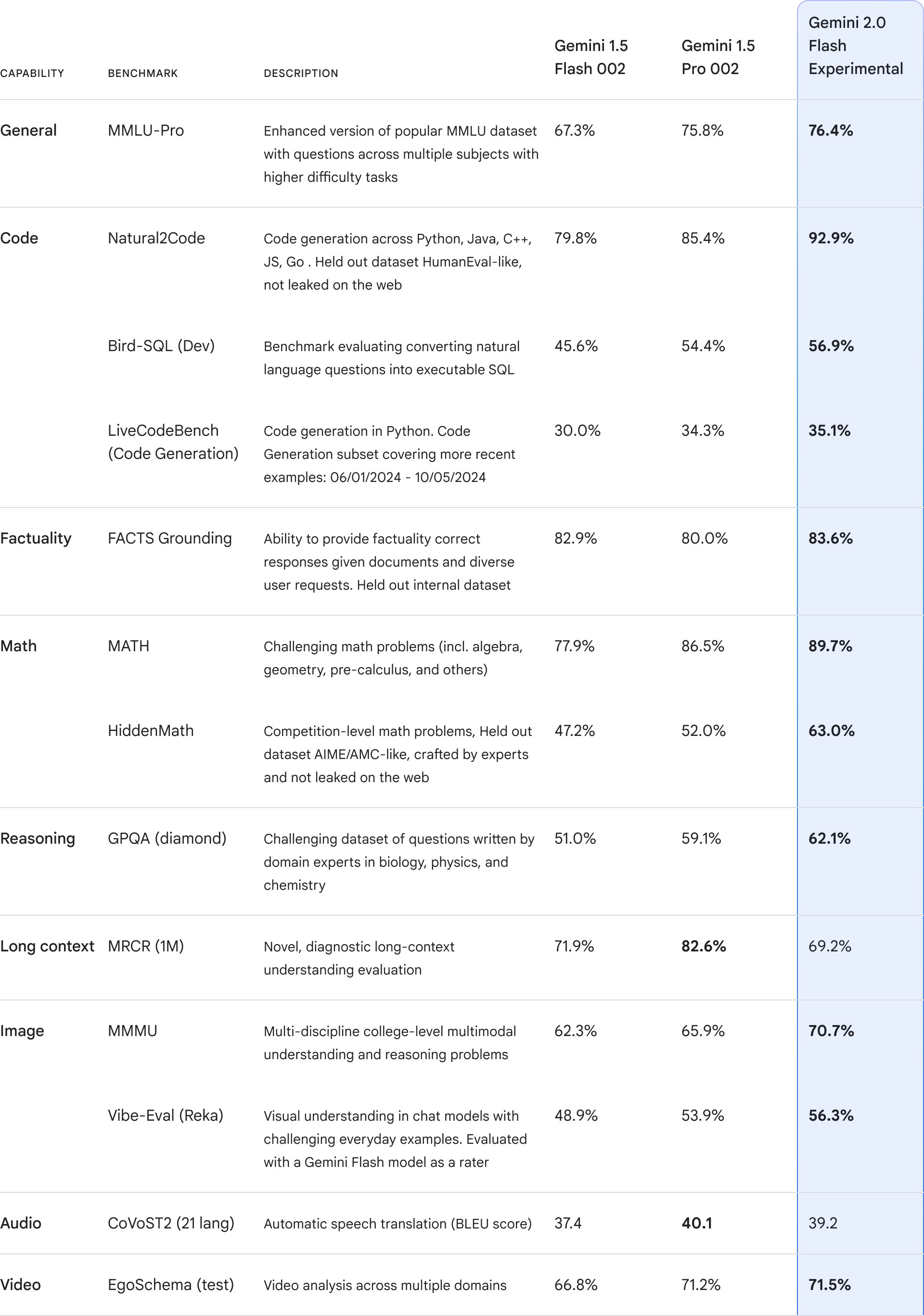
在功能方面,2.0 Flash 也实现了重大突破:
- 支持文本、图像、视频和音频等多模态输入。
- 新增多模态输出能力,可以将文本与 AI 生成的图像结合。
- 提供灵活的多语言 TTS (文本转语音) 功能。
- 能够直接调用 Google 搜索、代码执行以及第三方自定义功能。
Gemini 2.0 Flash Thinking
Gemini 2.0 Flash Thinking 是一种实验性模型。经过训练后,该模型在回答问题时能够生成其完整的「思考过程」。因此,相比基础版 Gemini 2.0 Flash 模型,思考模式在问题解答时具有更强的推理能力。
限制
思考模式作为实验性模型,存在以下限制:
- 输入限制为 32k Tokens。
- 仅支持文本和图片输入。
- 输出限制为 8k Tokens。
- 输出仅限于文本格式。
- 不支持搜索功能或代码执行等内置工具
试用 Gemini 2.0
开发者现在可以通过以下渠道体验 Gemini 2.0 Flash 和 Gemini 2.0 Flash Thinking:
目前,所有开发者都可以使用多模态输入和文本输出功能,而文本转语音和图像生成功能则向早期合作伙伴开放。更多型号的模型预计将于 2025 年 1 月推出。
此外,Google 还推出了新的多模态实时 API,支持实时音频、视频流输入处理,并且可以灵活组合多种工具。要了解更多关于 Gemini 2.0 Flash 和多模态实时 API 的细节,请访问开发者博客。
Gemini 2.0 正式登陆 Gemini 助手应用
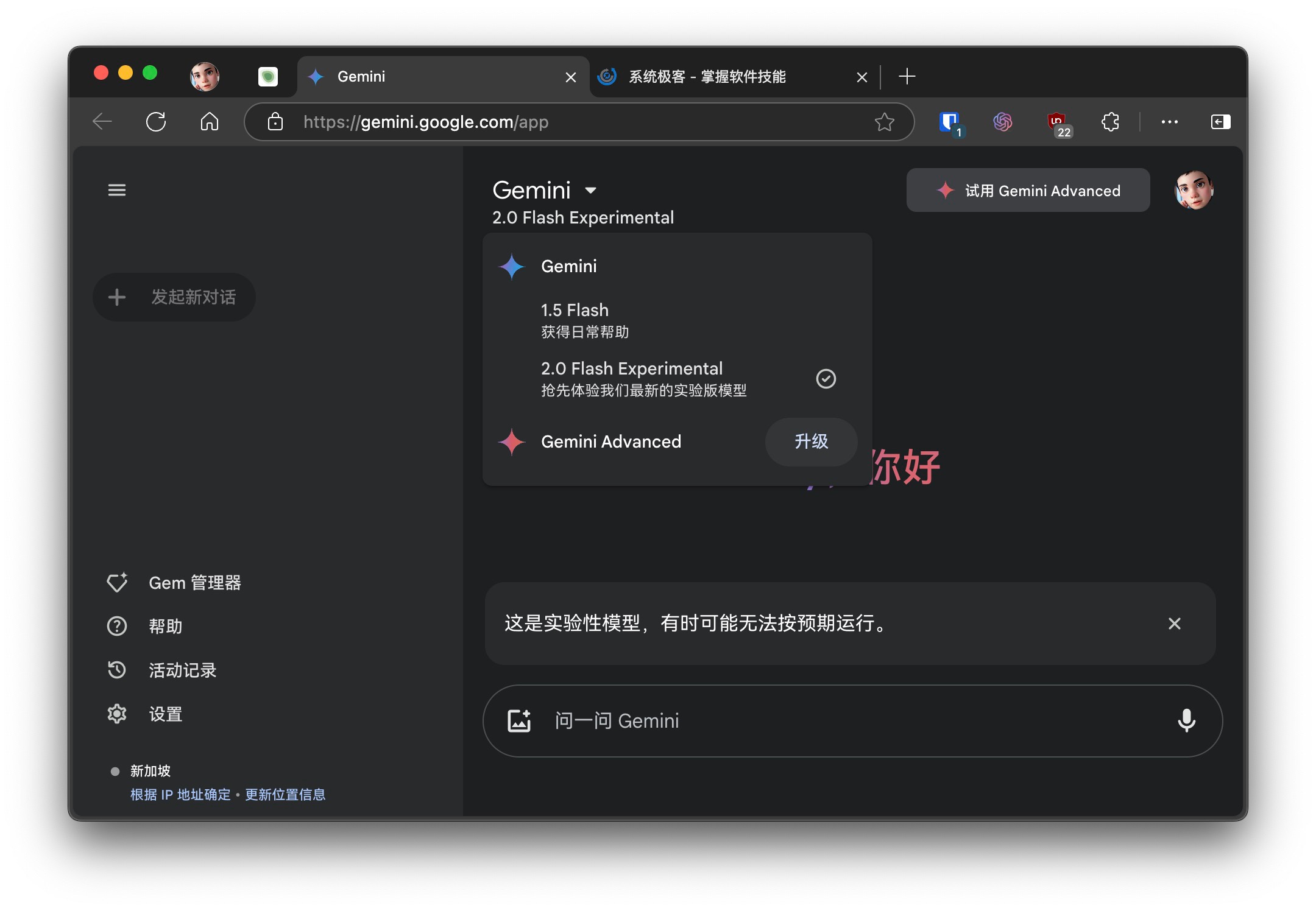
从现在开始,全球的 Gemini 和 Gemini Advanced 用户都可以在桌面版和网页版中,通过模型选择菜单,来体验经过聊天优化的 Gemini 2.0 Flash 实验版。这项功能很快也将登陆 Gemini 移动应用,让用户能随时随地体验更智能的 AI 助手服务。
Google 还计划在 2025 年初将 Gemini 2.0 的强大功能引入到更多产品中,敬请期待。





最新评论
也有可能是电脑过热
关闭「安全启动」或改用 grub 之后。通过 grub 启动 Windows 而不使用 UEFI 的 Windows Boot Manager,「设备加密」会认为启动路径不可信,就会彻底隐藏。
应用安装失败,错误消息: 从 (Microsoft.NET.Native.Framework.2.2_2.2.29512.0_x64__8wekyb3d8bbwe.Appx) 使用程序包 Microsoft.NET.Native.Framework.2.2_2.2.29512.0_x64__8wekyb3d8bbwe 中的目标卷 C: 执行的部署 Add 操作失败,错误为 0x80040154。有关诊断应用部署问题的帮助,请参阅 http://go.microsoft.com/fwlink/?LinkId=235160。 (0x80040154)
之前装双系统时关了BitLocker,后来找不大设备加密了(原本有的)是怎么回事