Google 开源了一款名为 Magika 的工具,它由 AI 技术驱动,旨在帮助用户迅速、准确地识别出各种二进制和文本文件的类型。Magika 内置了一个专门研发,且经过极致优化的深度学习模型,让它在普通 CPU 上也能够实现毫秒级别的精准识别。
现在,你就可以访问 Magika 的在线 Demo,或者运行pip install magika命令,它其作为 Python 库或者独立的命令行工具来使用。
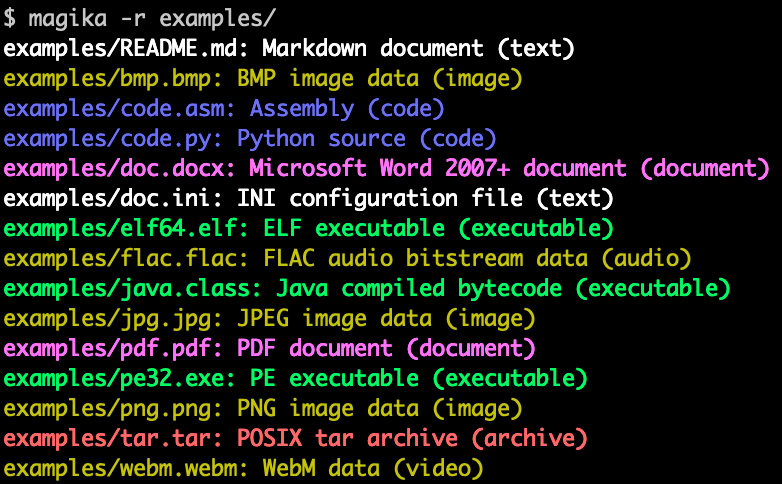
为什么文件类型识别很困难
从计算机诞生之初,准确地识别文件类型就一直是处理文件时的关键一步。比如 Linux 系统,就内置了libmagic和file工具,这些工具 50 多年来已经成为文件类型识别的标准。不仅是 Web 浏览器和代码编辑器,还有很多其他软件,都依赖这个功能来决定怎样正确地显示文件内容。例如,现代的代码编辑器会根据文件类型,来选择不同的代码高亮方案,以便开发者在编写新文件时获得更好的辅助。
但是,每种文件格式都有自己的独特结构,或者结构不明显,所以准确识别文件类型一直是一个众所周知的难题。特别是文本格式和编程语言,它们之间的结构差异很小,识别起来就更有挑战性。直到现在,libmagic和大部分的文件识别工具都还是靠一堆手写的规则,或启发式方法来区分不同的文件格式。
由于人工制定的规则很难面面俱到,这种手工方式不仅耗时,还容易出错。放在安全领域,这个问题就更加严峻了,因为攻击者总是会通过各种特制的恶意文件来试图欺骗识别系统。
Magika 的优势
面对文件类型识别的挑战,Google 研发了 Magika,这是一个革命性的、基于人工智能技术的文件类型识别系统。Magika 的核心是一个量身定制、极致优化的深度学习模型。这个模型不仅使用了 Keras 进行构建和训练,而且它的文件体积极小,仅约 1MB。在实际应用中,Magika 采用了 Onnx 作为运算引擎,确保了即使在普通 CPU 上,也能实现毫秒级的精准文件类型识别。
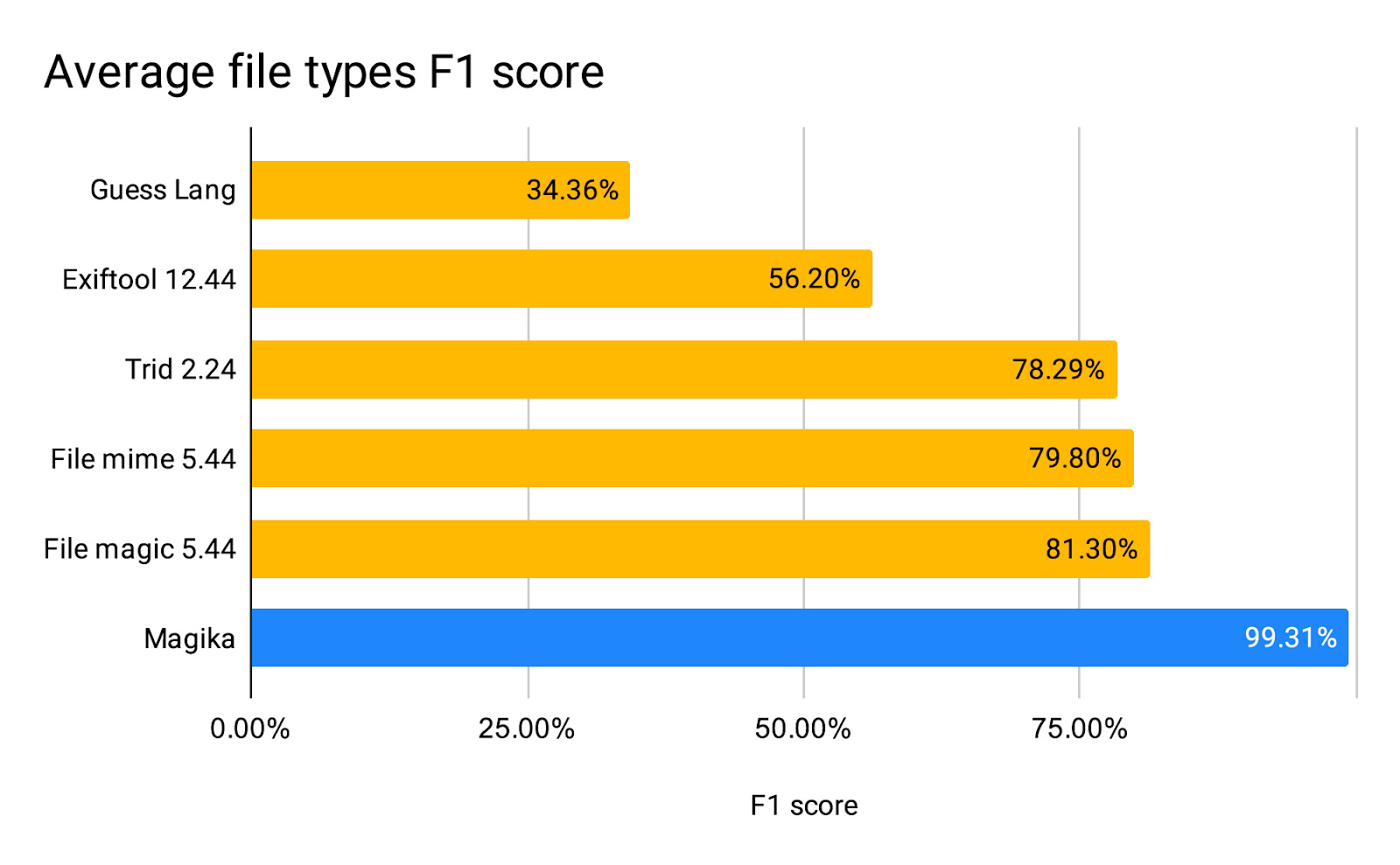
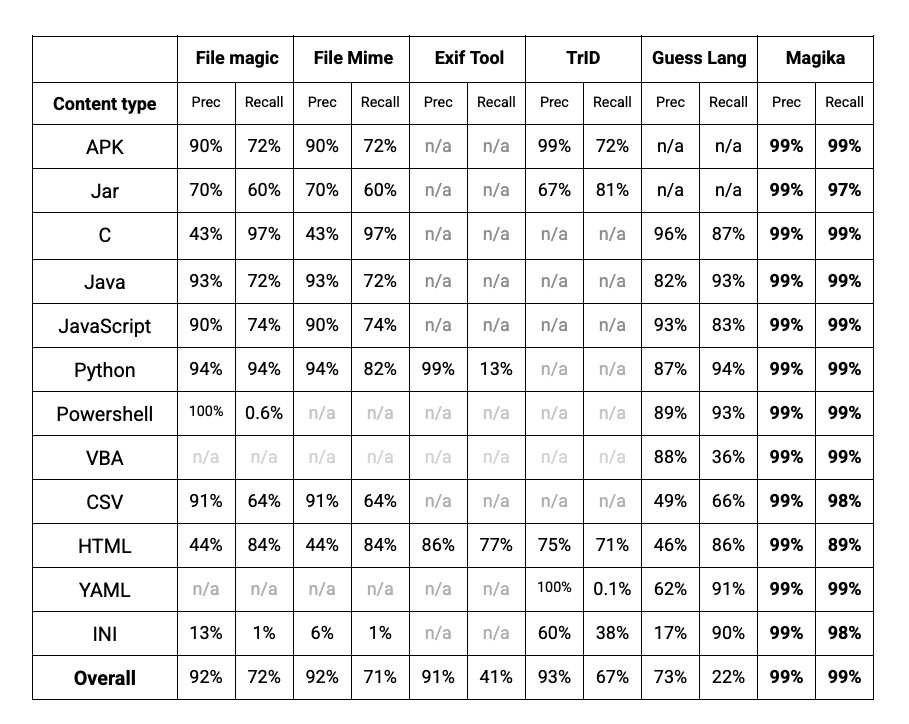
就性能而言,Magika 凭借先进的 AI 模型和庞大的训练数据集,在一项涵盖超过 100 种文件类型、包含 100 万个文件的综合性能评估中,相较于其他现有工具,准确率提高了大约 20%。在以下表格中,详细列出了按文件类型分类的识别结果。对于文本文件的识别,包括那些会难倒其他工具的代码文件和配置文件,Magika 展现了显著的性能优势。
Magika 在 Google 的实际运用
在 Google,Magika 正在被广泛地应用,以增强用户的安全防护。它确保了 Gmail、Drive 和 Safe Browsing 等服务中的文件能够被正确地识别,并分配到合适的安全检查及内容策略扫描系统中。
通过分析每周处理的数以千亿计的文件,使用 Magika 进行文件类型识别的准确性,比之前依靠手动规则设定的系统,提高了 50%。这样显著的性能提升意味着,我们能够利用专门针对恶意文件的 AI 扫描器,对更多(增加了 11%)的文件进行检查,并且将无法识别的文件比例减少到了仅有的 3%。
此外,Magika 将很快与 VirusTotal 进行集成,这将进一步增强该平台现有的 Code Insight 功能。Magika 会在文件被送往 Code Insight 进行分析之前进行预筛选,能显著提高平台的处理效率和准确性。得益于 VirusTotal 的合作特性,这种集成将直接推动全球网络安全生态系统的发展,共同营造一个更加安全的数字环境。
Code Insight 功能利用 Google 的生成式 AI 技术对恶意代码进行分析和识别。
为什么要开源 Magika
将 Magika 开源是为了帮助其他软件提升文件识别的准确度,并为研究者们提供一个在大规模上准确识别文件类型的可靠方法。
现在,任何人都可以免费下载:
- 在 Github 上下载 Magika 代码和模型(基于 Apache 2.0 开源许可证)。
- Google 提供了一个实验性的 npm 包,以供尝试和使用。
此外,Magika 还可以作为一个独立的工具或者 Python 库来使用,你可以通过 pypi 包管理器非常方便地安装。只需要在命令行中输入pip install magika,过程不需要 GPU 支持。




最新评论
你当前登录的用户不是管理员账户(没在administrators组中)?
奇怪,为啥我已经右键以管理员运行uup_download_windows了cmd里还提示我需要管理员权限运行
valeo@DESKTOP-BHEH91Q:~$ sudo systemctl is-active docker System has not been booted with systemd as init system (PID 1). Can't operate. Failed to connect to bus: Host is down 这个问题怎么解呀各路大神
Win11更改任务栏为顶部,把03改成01操作后没变化,在此操作发现注册表又还原回为03。 也就是说改注册表也是改不了,不知道为什么WIN11要把这个功能去掉,又影响了什么,一个系统升级改来改去。