OpenAI 正式推出 GPT-5.2 模型家族!无论是处理电子表格、制作演示文稿、编写代码,还是图像理解、长文本分析、工具调用,乃至处理多步骤的复杂项目,它都展现出了前所未有的强大能力。
基准测试
在多项核心基准测试中,GPT-5.2 全面刷新了业界纪录。尤其是在 GDPval 测试中,面对覆盖 44 种职业的专业知识任务,其表现甚至超越了人类专家。
| 评测项目 | 类别 | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|---|
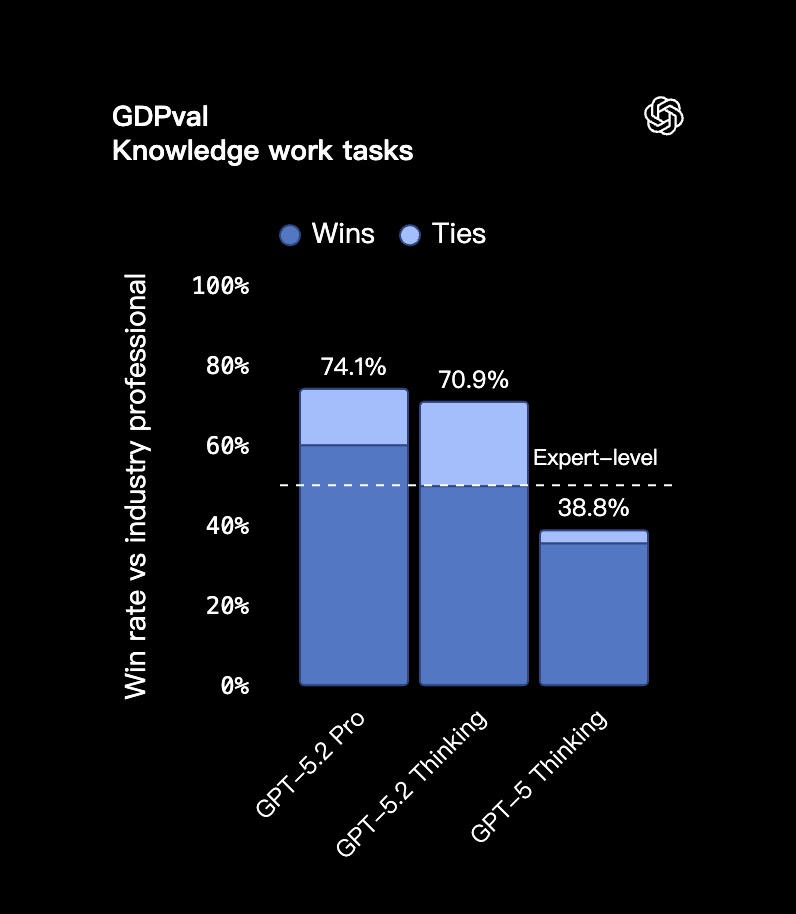
| GDPval (胜出或平局) | 知识工作任务 | 70.9% | 38.8% (GPT-5) |
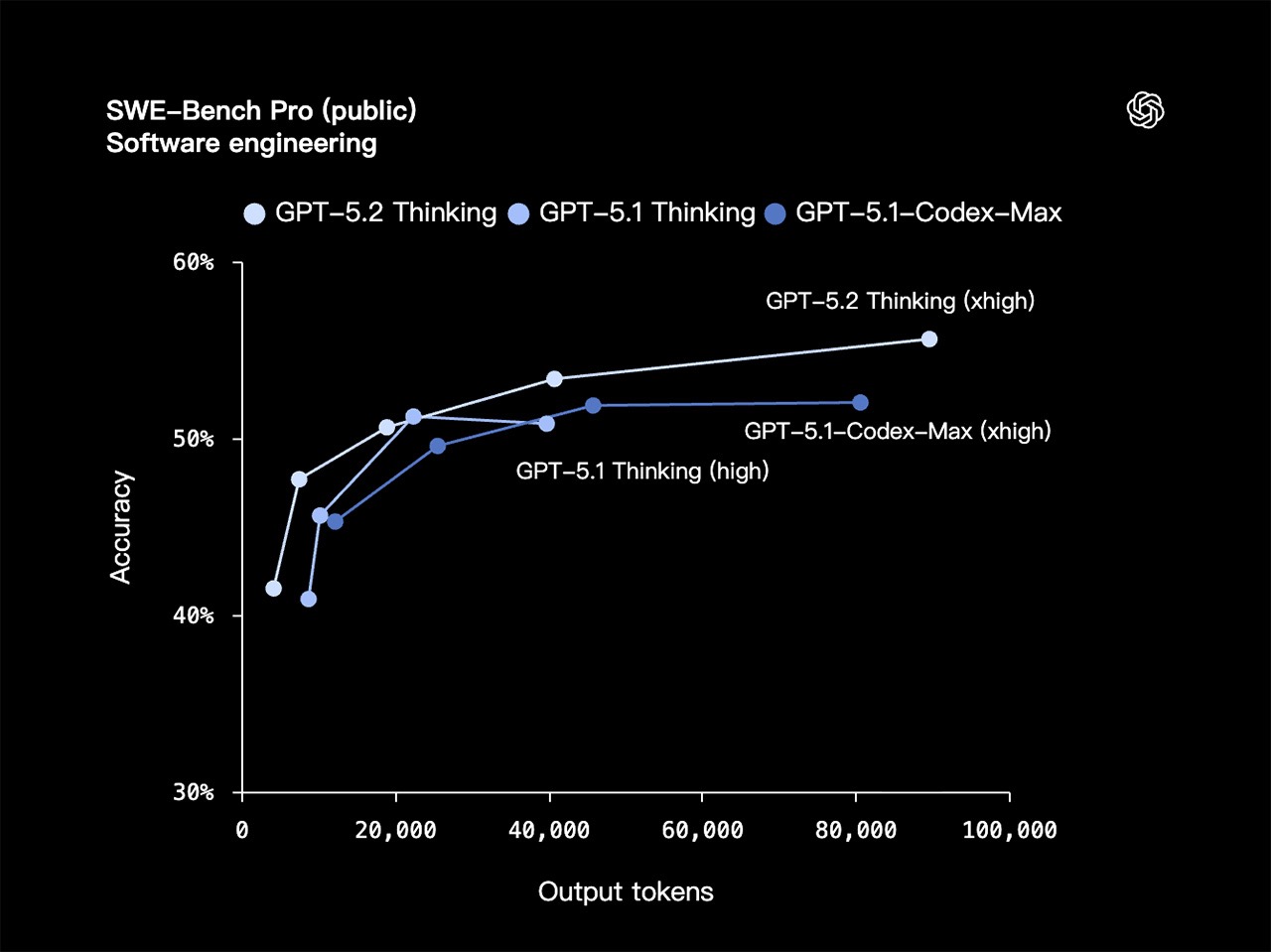
| SWE-Bench Pro (public) | 软件工程 | 55.6% | 50.8% |
| SWE-bench Verified | 软件工程 | 80.0% | 76.3% |
| GPQA Diamond (无工具) | 科学问答 | 92.4% | 88.1% |
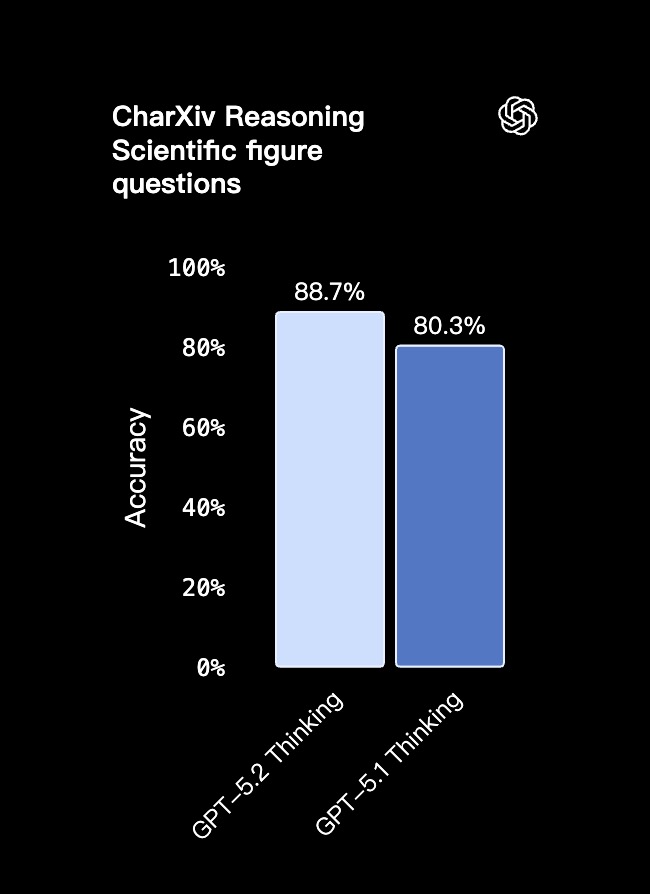
| CharXiv Reasoning (含 Python) | 科学图表问答 | 88.7% | 80.3% |
| AIME 2025 (无工具) | 竞赛数学 | 100.0% | 94.0% |
| FrontierMath (Tier 1–3) | 高等数学 | 40.3% | 31.0% |
| FrontierMath (Tier 4) | 高等数学 | 14.6% | 12.5% |
| ARC-AGI-1 (Verified) | 抽象推理 | 86.2% | 72.8% |
| ARC-AGI-2 (Verified) | 抽象推理 | 52.9% | 17.6% |
GPT 5.2 模型性能深度解析
经济价值实战任务
- 在衡量 44 种职业特定知识任务的 GDPval 评测中,GPT-5.2 不仅创造了历史最高成绩,也是 OpenAI 首个达到乃至超越人类专家水平的模型。
- 经过人类专家的严格评审,在演示文稿、电子表格等专业交付物对比中,GPT-5.2 Thinking 有 70.9% 的案例击败或追平了行业顶尖专家。
代码编程
在严格衡量真实世界软件工程能力的 SWE-Bench Pro 测试中,GPT-5.2 Thinking 以 55.6% 的成绩创下新纪录。和只考察 Python 的 SWE-bench Verified 不同,SWE-Bench Pro 覆盖了 4 种编程语言,难度更高、挑战更全面,也更加贴近工业级实战场景。
- 对于日常开发而言,这意味着模型在调试生产代码、实现功能需求、重构大型代码库以及端到端交付修复方案时更为可靠,所需要的人工干预也更少。
- 不少早期测试者反馈,它在处理复杂或非传统的 UI 交互(尤其是涉及 3D 元素的界面)时表现突出,堪称全栈工程师的高效伙伴。往往只需要一个提示词,就能生成令人印象深刻的结果。
事实性与准确度
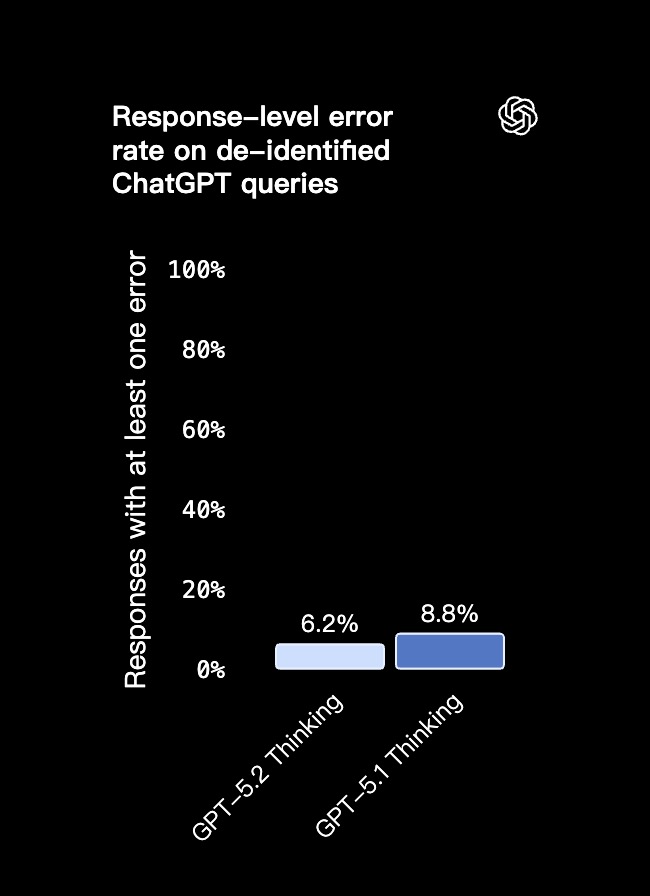
GPT-5.2 Thinking 显著减少了长期困扰业界的「幻觉」问题。在一组去标识化的 ChatGPT 查询测试中,错误回复减少了 30%。对专业用户来说,这意味着在研究、写作、分析或决策支持等工作中,模型的可靠性更高、风险也更低。
超长上下文
GPT-5.2 Thinking 在长文本推理能力上,树立了新的标杆:
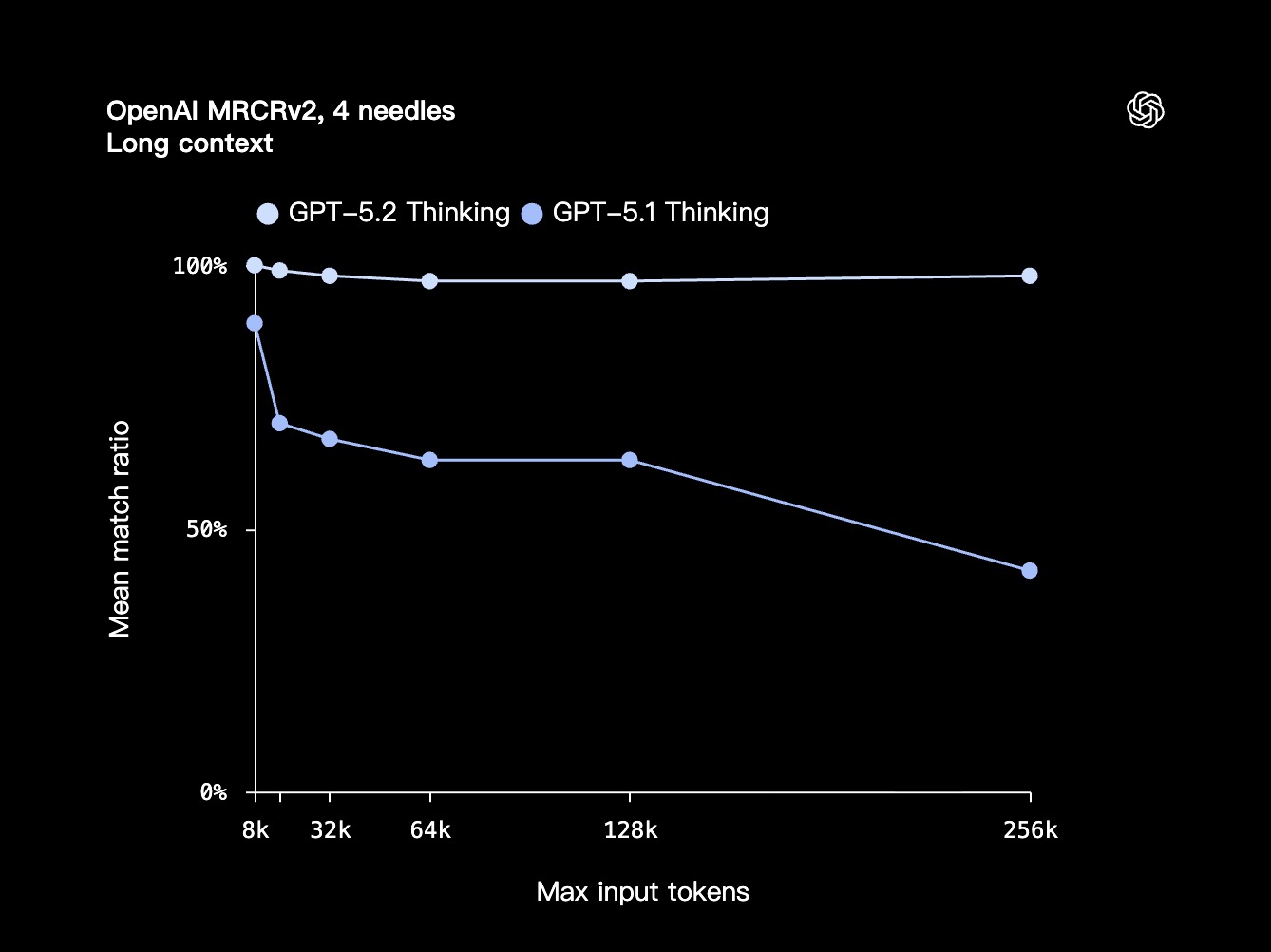
- 在专门考察模型整合分散信息能力的 OpenAI MRCRv2 评测中表现领先。
- 在处理深度文档分析等需要跨数十万 Token 信息的任务时,准确率大幅超越了 GPT-5.1 Thinking。
- 尤其在扩展至 256k Token 的 4-needle MRCR 变体测试中,它是首个准确率接近 100% 的模型。
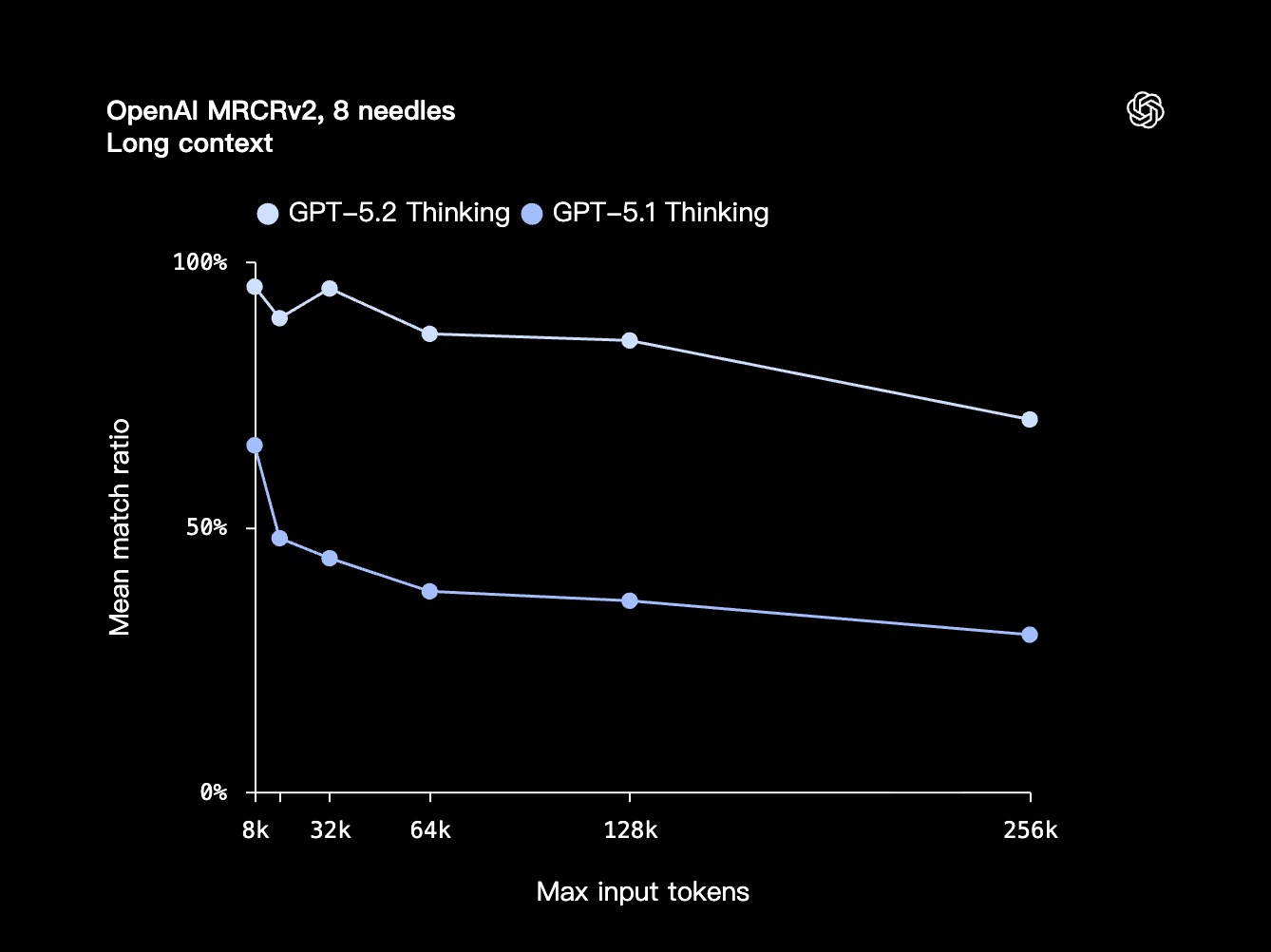
在实际应用中,这就让专业人士能更高效地处理海量文档。无论是报告、合同、研究论文、笔记还是跨文件项目,GPT-5.2 都能在数十万 Token 的跨度内,保持逻辑连贯与精准。天然就适合深度分析与多源复杂工作流。
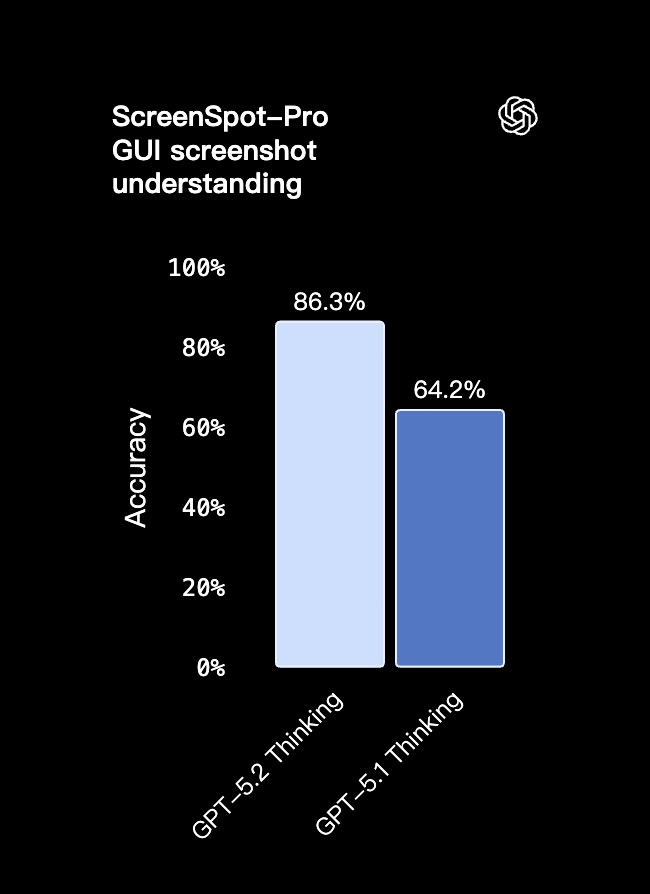
视觉能力
GPT-5.2 Thinking 也是目前 OpenAI 视觉能力最强的模型,在图表推理与软件界面理解上的错误率降低了约一半。
- 对专业用户而言,模型能更精确地解读仪表盘、产品截图、技术图纸和可视化报告,能为金融、运营、工程、设计及客户支持等依赖视觉信息的领域带来更强助力。
- 与前代模型相比,GPT-5.2 Thinking 对图像中元素位置关系的理解更为深刻,尤其擅长解决依赖相对布局的问题。
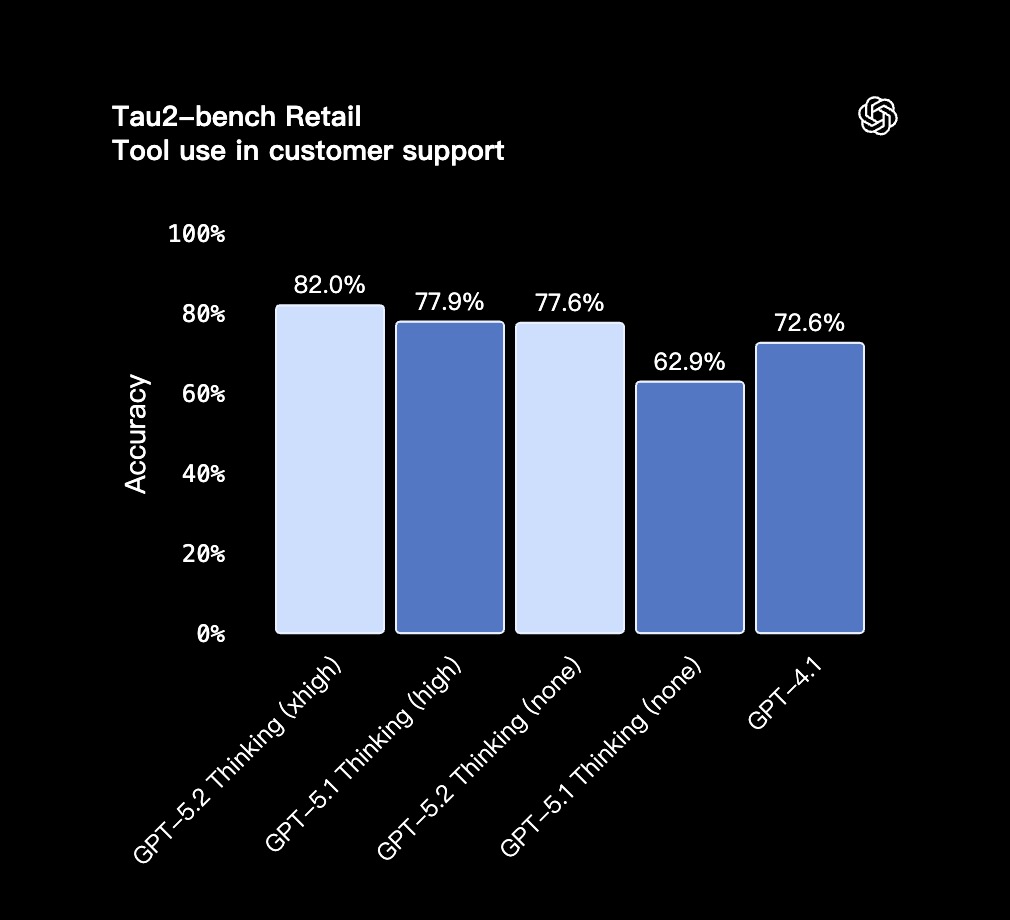
工具调用与智能体协作
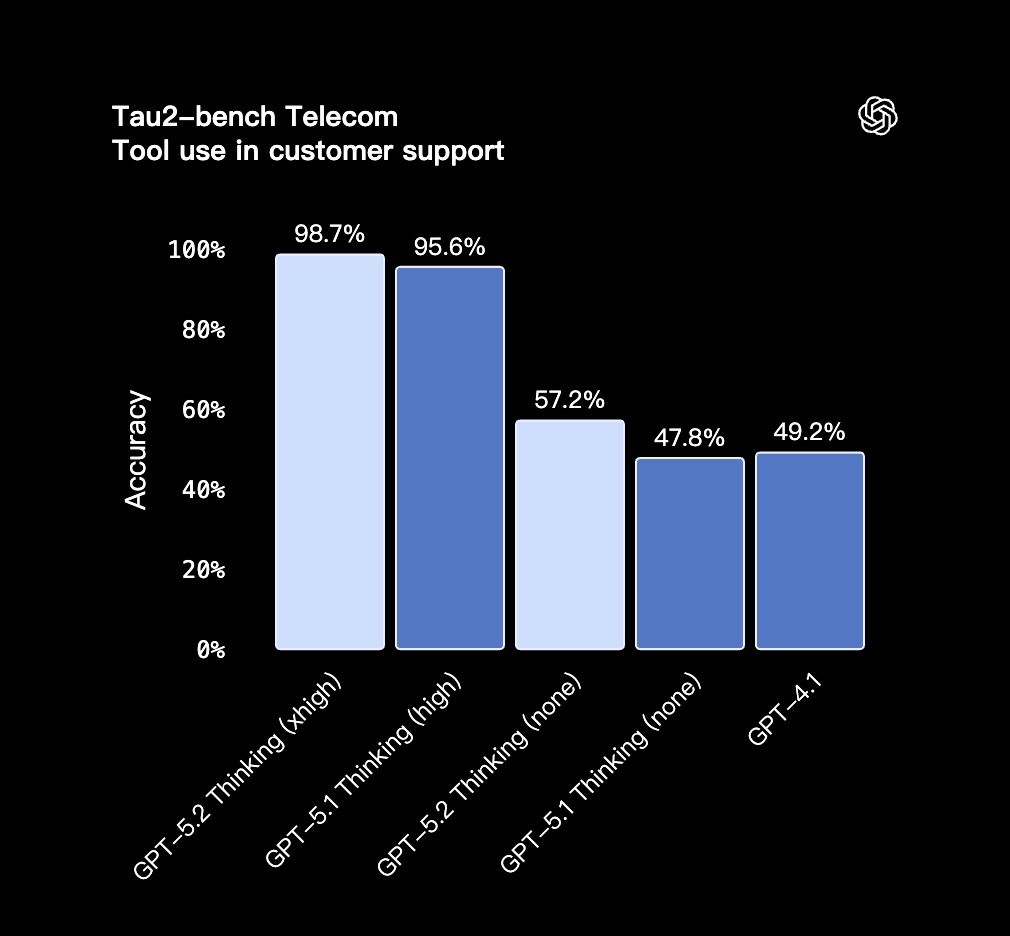
- GPT-5.2 Thinking 在 Tau2-bench Telecom 测试中取得了 98.7% 的领先成绩,展现了在长链条、多轮任务中,稳定可靠的工具使用能力。
- 在延迟更敏感场景中,GPT-5.2 Thinking 在
reasoning.effort='none'模式下的表现也大幅领先于 GPT-5.1 和 GPT-4.1。
科学与数学
OpenAI 表示,GPT-5.2 Pro 与 GPT-5.2 Thinking 是目前最适合辅助和加速科学研究的模型。
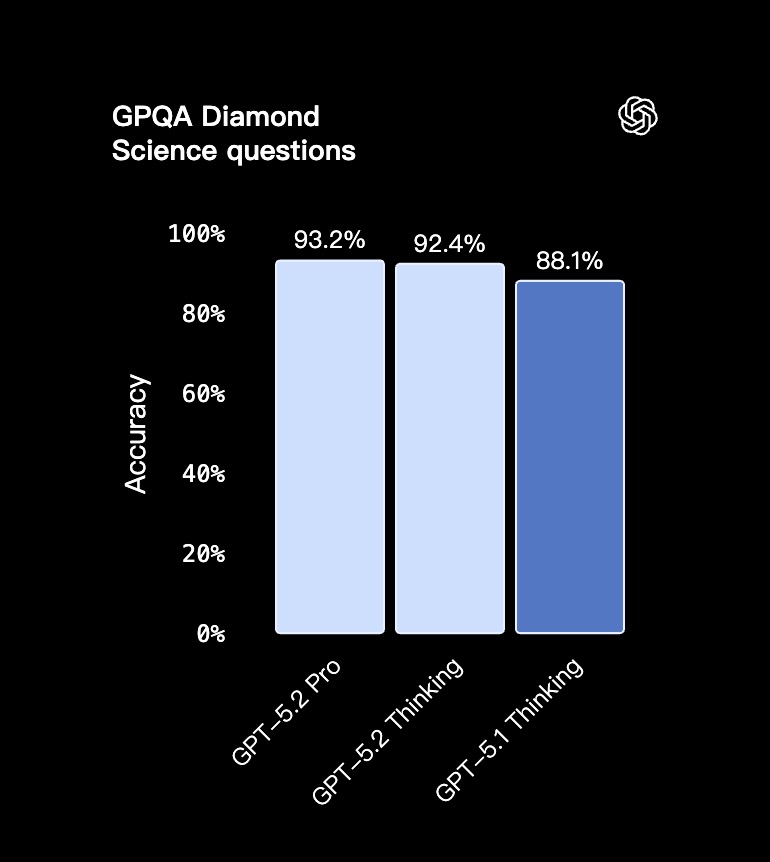
- 在 GPQA Diamond(研究生级别的 Google-proof 问答测试)中,GPT-5.2 Pro 取得了 93.2% 的成绩,GPT-5.2 Thinking 则以 92.4% 紧随其后。
- 在专家级数学评测 FrontierMath(Tier 1–3)中,GPT-5.2 Thinking 刷新了最高纪录,成功解决了 40.3% 的难题。

ARC-AGI 2:通用推理突破
- 在衡量通用推理能力的 ARC-AGI-1(Verified)测试中,GPT-5.2 Pro 成为首个突破 90% 的模型。相比去年 o3-preview 87% 的成绩,性能显著提升,所需的成本降低了约 390 倍。
- 在难度更高、考察流体智力(Fluid Reasoning)的 ARC-AGI-2(Verified)测试中,GPT-5.2 Thinking 以 52.9% 刷新了思维链模型的纪录。GPT-5.2 Pro 更是达到 54.2%,进一步拓展了模型在抽象推理上的能力边界。
GPT-5.2 模型家族
在使用 ChatGPT 时,你将能明显感受到 GPT-5.2 的体验更加顺滑——回答结构更清晰、稳定性更强,同时保持着自然的对话风格。
- GPT-5.2 Instant:面向高频日常使用场景,是工作与学习的效率利器。它在延续 GPT-5.1 Instant 轻松友好风格的基础上,在信息检索、操作指导、技术写作和翻译等任务上的表现都更加出色。
- GPT-5.2 Thinking:专为深度工作打造,帮助用户以更高完成度处理复杂任务。它在编程、长文档总结、文件问答、分步骤解决数学与逻辑问题,以及规划复杂决策等场景上的表现尤为出色。
- GPT-5.2 Pro:最强大、最值得信赖的旗舰选择,面向「高质量答案值得等待」的用户。它在编程等复杂场景中的重大错误明显更少,整体性能更为稳健可靠。
模型名称 ChatGPT & API
| ChatGPT | API |
|---|---|
| ChatGPT‑5.2 Instant | GPT‑5.2-chat-latest |
| ChatGPT‑5.2 Thinking | GPT‑5.2 |
| ChatGPT‑5.2 Pro | GPT‑5.2 Pro |
使用价格
| 模型 | 输入 | 缓存输入 | 输出 |
|---|---|---|---|
| gpt-5.2/gpt-5.2-chat-latest | $1.75 | $0.175 | $14 |
| gpt-5.2-pro | $21 | – | $168 |
| gpt-5.1/gpt-5.1-chat-latest | $1.25 | $0.125 | $10 |
| gpt-5-pro | $15 | – | $120 |

最新评论
32位 Windows 版本,没毛病
32位下好后右键属性一看版本型号、安装包信息都TM是64位的
不错,还非常贴心的附上了下载链接。
然而评估版本是不能激活的,这坑爹文章