GPT-5.4 正式发布!它是 OpenAI 迄今为止,在专业办公领域能力最强、效率最高的前沿模型。与此同时,为了满足复杂任务对极致性能的需求,ChatGPT 和 API 还同步推出了 GPT-5.4 Pro。
GPT-5.4 是逻辑推理、代码编写与 AI 智能体工作流的集大成者。它不仅继承了 GPT-5.3-Codex 领先业界的编程能力,还大幅优化了在各类工具、软件环境,以及表格、演示文稿、文档处理等专业场景下的表现。
简单来说,它能以极高的准确度与效率,一次性交付符合预期的成果,帮你告别反复沟通与返工操作。
在 ChatGPT 中
- GPT-5.4 Thinking 现已支持前置输出「思考计划」,还能在生成回复的过程中「中途调整方向」——无需多轮对话,即可输出完美契合需求的结果。
- 它还进一步强化了「深度网络搜索」能力,在处理需要长时间推理的追问时,展现出了更强的上下文维持能力。
在 Codex 和 API 端
- GPT-5.4 是 OpenAI 首个具备原生顶尖「计算机操作能力」(Computer-use)的通用模型,赋予了 AI 智能体直接操控电脑、跨应用执行复杂工作流的能力。
- 提供高达 100 万 Token 的上下文支持,让 AI 智能体能在超长周期内,从容完成任务规划、执行与验证。
- 新增的「工具搜索」机制,优化了模型在庞大工具生态与连接器中的协作表现。能帮助 AI 智能体在不牺牲「智能度」的前提下,高效定位并调用最合适的工具。
- 除此之外,它还是 OpenAI 迄今为止「Token 利用率」最高的推理模型。面对同类问题时,Token 消耗要远低于 GPT-5.2,不仅极大降低了使用成本,更带来了飞一般的响应速度。
| GPT-5.4 | GPT-5.3-Codex | GPT-5.2 | |
|---|---|---|---|
| GDPval | 83.0% | 70.9% | 70.9% |
| SWE-Bench Pro | 57.7% | 56.8% | 55.6% |
| OSWorld-Verified | 75.0% | 74.0%* | 47.3% |
| Toolathlon | 54.6% | 51.9% | 46.3% |
| BrowseComp | 82.7% | 77.3% | 65.8% |
凭借在通用推理、编程和专业知识型工作上的全面进化,GPT-5.4 在 ChatGPT、API 和 Codex 全平台,为开发者带来了更可靠的 AI 智能体、更迅捷的开发工作流,以及更高质量的输出成果。
GPT-5.4 主要更新
知识型工作
基于 GPT-5.2 扎实的通用推理底座,GPT-5.4 在专业人士最看重的「现实任务」中,交出了一份更稳定、更出色的答卷。
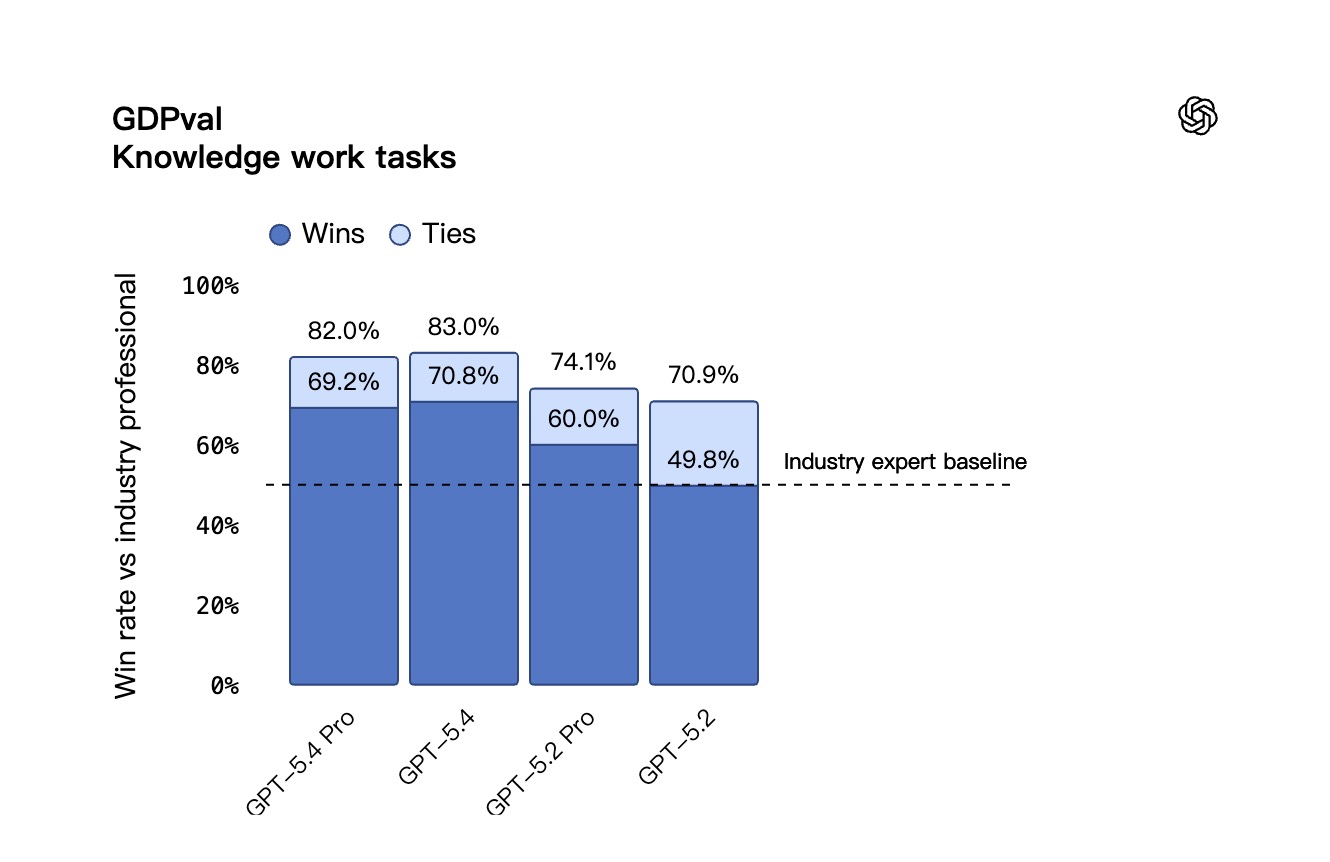
- 在 GDPval 测试中,GPT-5.4 刷新了行业天花板。它在 83.0% 的对比场景中打平或超越了人类资深专家,前代 GPT-5.2 的成绩仅为 70.9%。
GDPval:涵盖 44 个职业,旨在评估 AI 智能体高质量知识型工作的产出能力。
OpenAI 投入了大量资源,重点提升了 GPT-5.4 创建与编辑表格、演示文稿、文档的能力。
- 在一项模拟初级投行分析师「电子表格建模」任务的内部基准测试中,GPT-5.4 获得了 87.3% 的平均分,大幅领先于 GPT-5.2 68.4% 的成绩。
- 在演示文稿专项评估中,人类评估员在 68.0% 的场景下更青睐 GPT-5.4 的作品。核心原因是:它拥有更优秀的美学设计、更丰富的视觉多样性,以及对图像生成能力的出色运用。
目前,你可以在 ChatGPT 中切换到 GPT-5.4 Thinking 或 Pro 模式,来体验这些强悍功能。企业版用户强烈推荐同步上线的「ChatGPT for Excel 插件」。此外,官方对 Codex 和 API 中的表格、幻灯片处理能力,也完成了全面升级。
为了让 GPT-5.4 真正成为现实场景中的工作利器,OpenAI 在降低模型幻觉、减少事实错误上持续发力,是有史以来最严谨求实的模型:
- 在用户标记为「存在事实错误」的脱敏提示词数据集中,相比 GPT-5.2,GPT-5.4 单条陈述的出错概率降低了 33%,整体回复包含错误的概率也下降了 18%。
计算机操作与视觉感知
作为 OpenAI 首个内建原生「计算机操作」(Computer-use)能力的通用模型,GPT-5.4 为开发者和 AI 智能体带来了关键性突破。对于想要构建可在真实环境中跨网页、跨软件系统执行任务的 AI 智能体而言,它无疑是当下最可靠的选择。
GPT-5.4 经过专项优化,可以轻松应对各类计算机操作任务:
- 它不仅精通代码编写,还能通过 Playwright 等自动化库操控计算机,更能根据屏幕截图,精准发出鼠标和键盘指令。
- 依托极强的可控性,开发者可通过提示词微调模型行为,让它完美适配特定业务逻辑。甚至还能自定义确认策略,在不同风险容忍度下,动态调整模型的安全边界。
在多项衡量计算机操作能力的基准测试中,GPT-5.4 的表现十分亮眼:
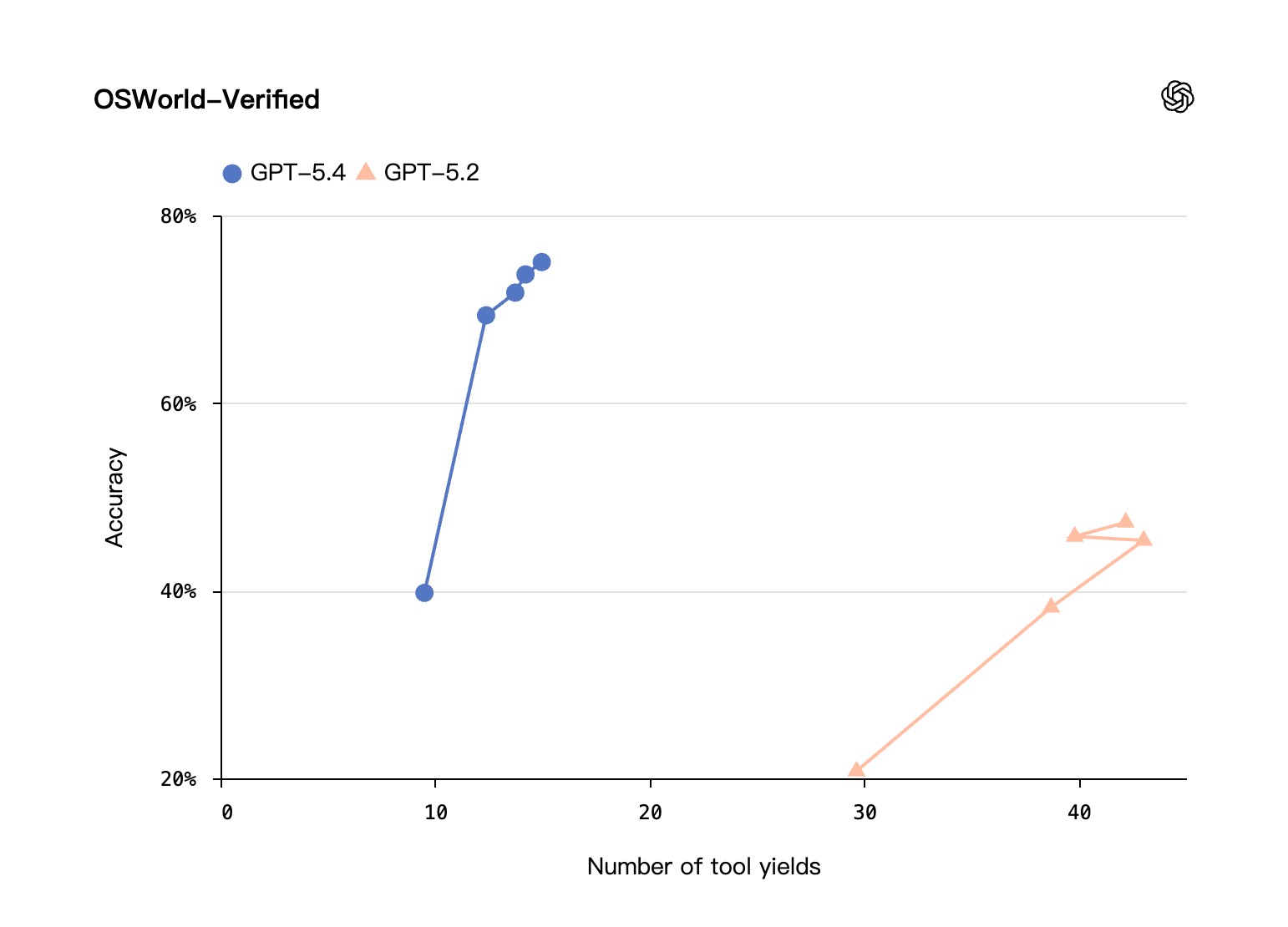
- 在 OSWorld-Verified 测试中,它以 75.0% 的成功率,大幅领先 GPT-5.2 47.3% 的成绩,还一举超越了 72.4% 的人类基准水平。
OSWorld-Verified:通过截图和键鼠操作,评估模型桌面环境导航能力的测试。
- 在 WebArena-Verified 浏览器操作测试中,GPT-5.4 结合 DOM 与截图驱动交互,取得了 67.3% 的成功率(GPT-5.2 为 65.4%)。
- 在同样考察浏览器操作能力的 Online-Mind2Web 测试中,它仅凭截图观察,就交出了 92.8% 的惊艳成绩,远超 ChatGPT Atlas 智能体模式 70.9% 的表现。
GPT-5.4 计算机操作能力的飞跃,核心源于其通用视觉感知能力的全面进化:
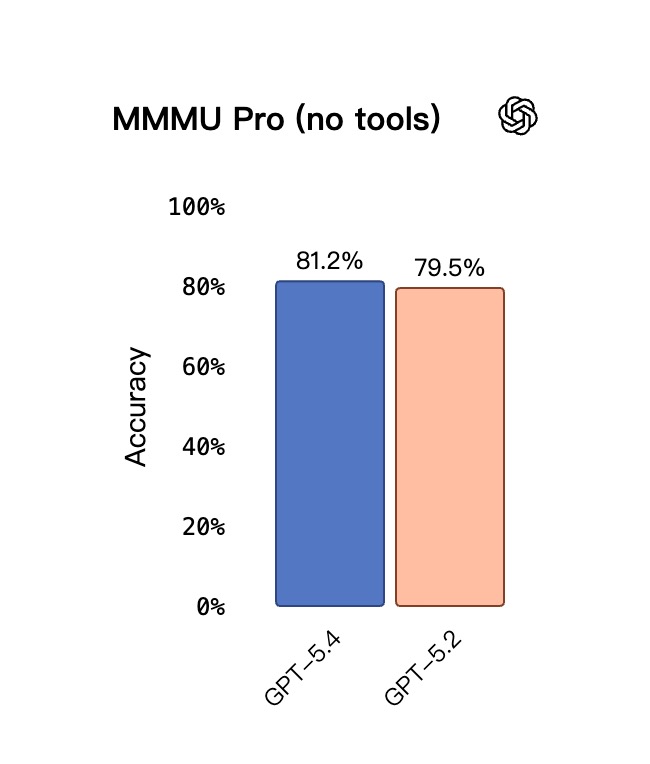
- 在 MMMU-Pro 视觉理解与推理评测中,即便不调用外部工具,GPT-5.4 也取得了 81.2% 的成功率,稳稳压过了 GPT-5.2 79.5% 的成绩。
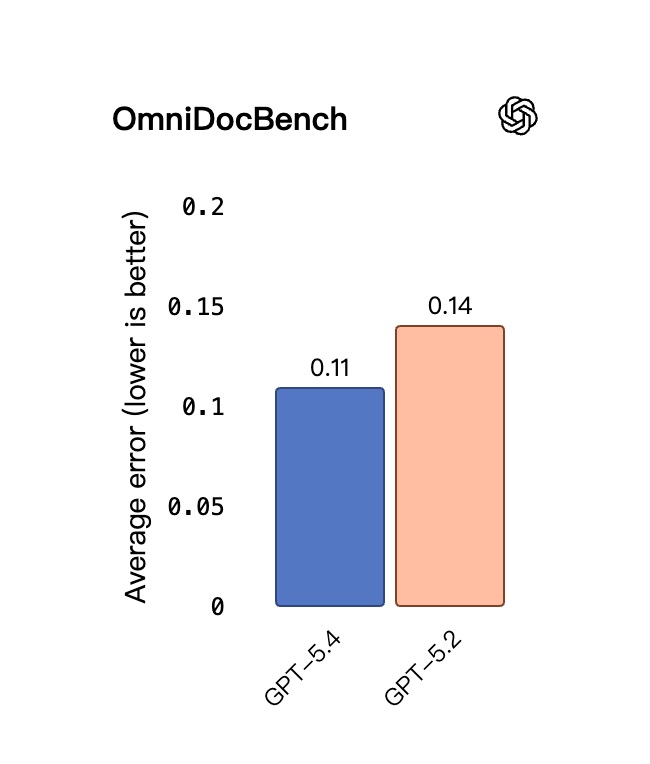
- 在 OmniDocBench 测试中,即便不启用 Thinking 模式,GPT-5.4 的平均错误率也已降到了 0.109,明显优于 GPT-5.2 的 0.140。
之外,针对高度依赖画面细节的密集型、高分辨率图像任务,OpenAI 进一步拉高了视觉理解的能力上限:
- 从 GPT-5.4 开始,API 新增了
original图像输入细节级别,最高支持 1024 万总像素,或单边最大 6000 像素的全保真感知。 - 原有的
high细节级别也完成了升级,现在支持 256 万总像素,或单边最大 2048 像素。 - 在早期用户测试中,开启
original或high细节模式后,模型在目标定位、图像理解、点击精准度等方面,均展现出了显著的性能提升。
代码编写
GPT-5.4 将 GPT-5.3-Codex 领先业界的编程能力,与顶尖的知识型工作、计算机操作能力深度融合。在面对长周期开发任务时,模型能更自如地调用工具、迭代代码,在极少人工干预的情况下,持续推进项目。
在 SWE-Bench Pro 测试中,它不仅追平,甚至小幅超越了 GPT-5.3-Codex,还在推理过程中保持了更低的延迟。
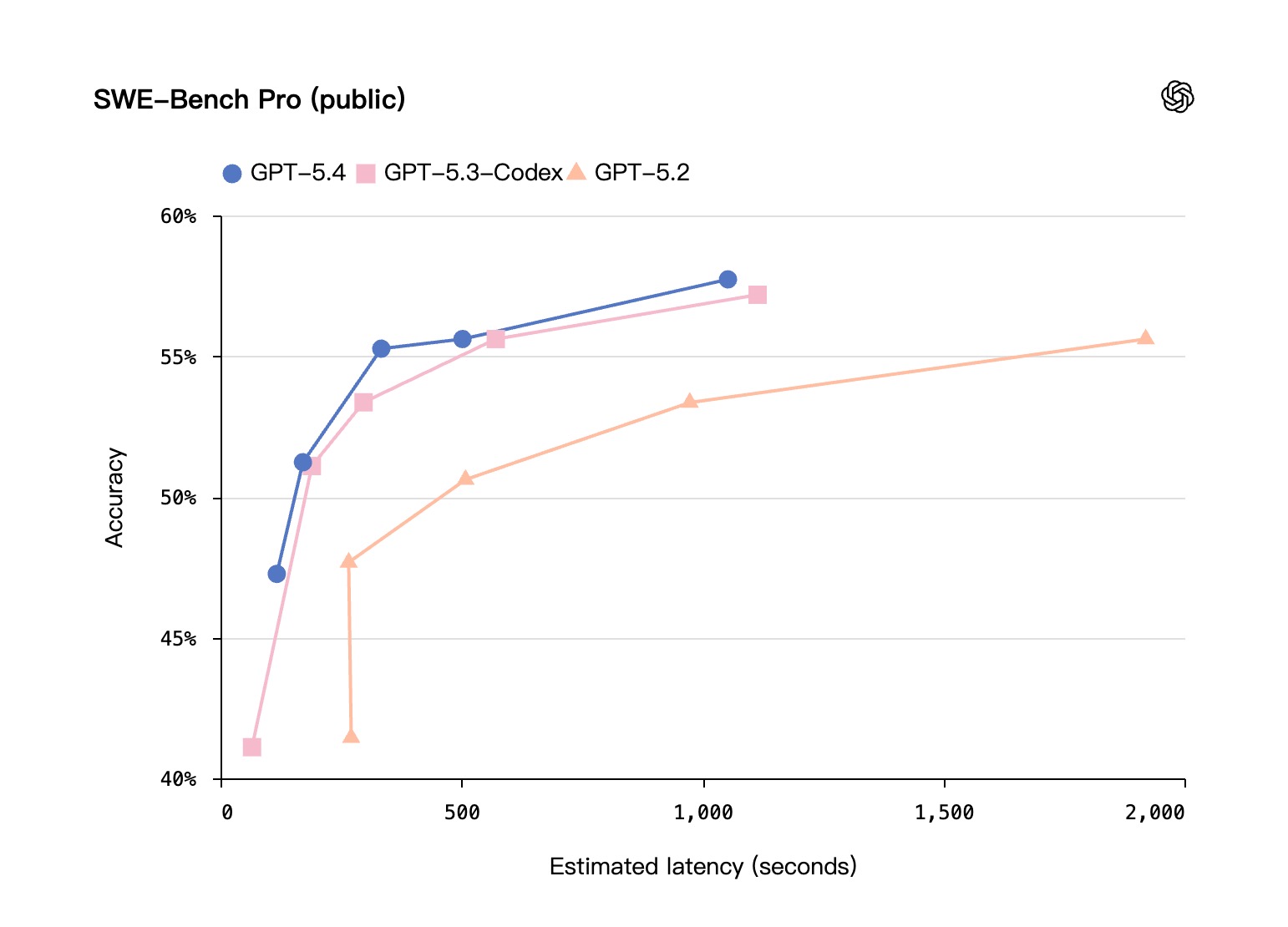
- 在 Codex 中启用
/fast模式后,GPT-5.4 的 Token 生成速度最高可提升 1.5 倍。内核能力与智能水平毫无缩水,实现了纯粹的速度飞跃。 - 这意味着,开发者在编码、迭代与调试时,能获得更流畅的体验,思路不再被打断。API 用户也可通过「优先处理」机制,获得同等的极速响应。
GPT-5.4 尤其擅长处理复杂的前端任务,其输出在美学设计与功能完整性上,均远超 OpenAI 此前发布的模型。
工具调用
有了 GPT-5.4,模型与外部工具的协同方式也迎来了质的飞跃。现在,AI 智能体能在更庞大的工具生态中自如穿梭,更精准地挑选所需工具,以更低的成本和延迟完成「多步工作流」。
工具搜索
在 API 端,GPT-5.4 引入了全新的「工具搜索」机制。面对海量可用工具,该机制能让模型始终保持极高的运行效率。
- 在过去,为模型配置工具时,必须在初始提示词中塞入所有工具定义。对于工具繁多的系统来说,这种做法不仅会在每次请求中强加成千上万的 Token——推高成本、拖慢响应速度,还会让上下文被大量(模型可能永远用不到的)信息填满。
- 而现在,GPT-5.4 只需接收一份轻量级的「可用工具列表」,同时启用「工具搜索」能力即可。当模型需要用到某个工具时,会(在当下)精准调取该工具的完整定义,并将其动态追加到当前对话上下文中。
这种「按需加载」的策略,大幅削减了重度工具工作流所需的 Token 消耗,同时保留了上下文缓存空间——让请求更快、使用成本更低。更重要的是,它让 AI 智能体能毫无压力地接入超大规模工具生态。比如,对于包含数万 Token 工具定义的 MCP 服务器来说,这种效率提升堪称颠覆性。
为验证该机制的实际效果,OpenAI 在 Scale 的 MCP Atlas 基准测试中抽取了 250 个任务,并启用了全部 36 个 MCP 服务器,对比了以下两种模式:
- 将所有 MCP 函数直接暴露在模型上下文中。
- 将所有 MCP 服务器置于「工具搜索」之后。
结果显示,在准确率完全一致的前提下,工具搜索将整体 Token 消耗硬生生降低了 47%。
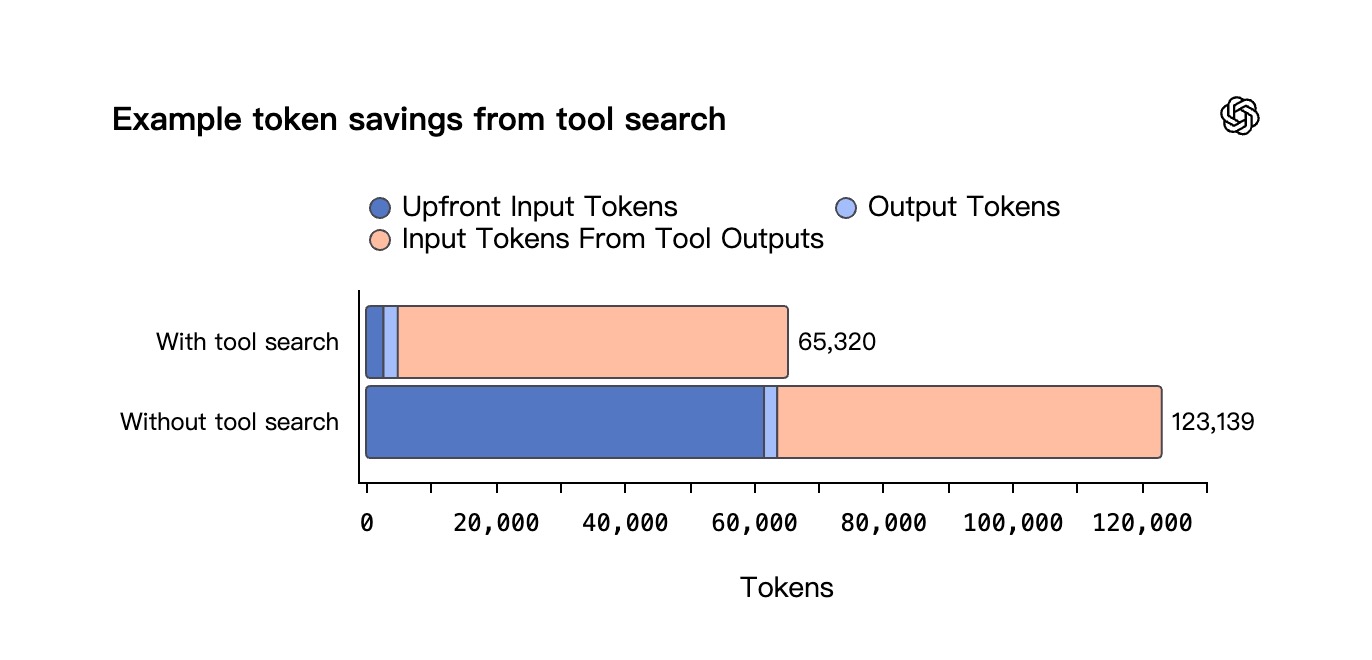
智能体级工具调用
GPT-5.4 进一步优化了「工具调用」机制,API 端的提升尤为显著:
- 在推理过程中决定何时、如何调用工具时,表现变得更加精准高效。
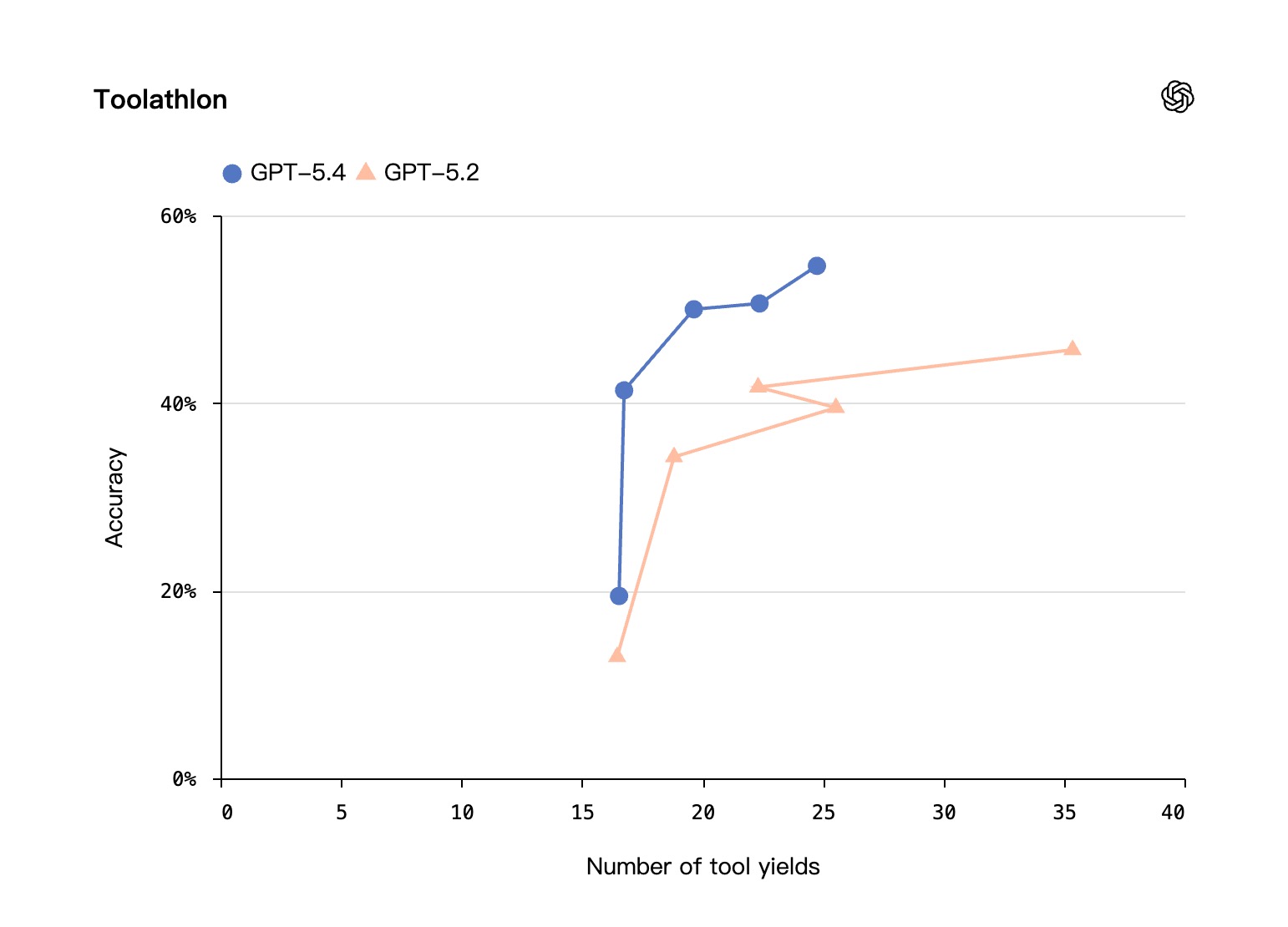
- 在 Toolathlon 测试中, 相比 GPT-5.2,GPT-5.4 以更少的交互轮数,实现了更高的准确率。
举个例子,当你要求 AI 智能体完成邮件读取、提取附件、上传文件、内容评分,再将成绩录入电子表格的全流程任务时,GPT-5.4 能行云流水般的一气呵成。
Toolathlon
Toolathlon:综合评测 AI 智能体利用真实世界工具和 API 完成多步任务能力的基准测试。
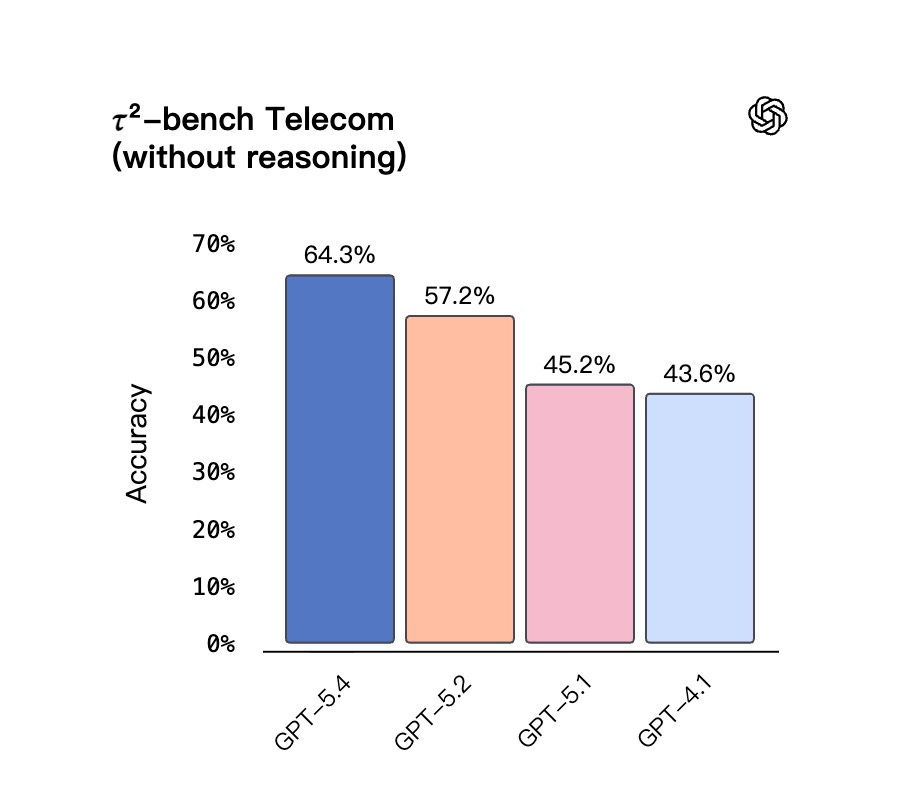
- 对延迟极其敏感、倾向于关闭推理过程的业务场景,GPT-5.4 同样比前代取得了显著进步。
网络搜索再进化
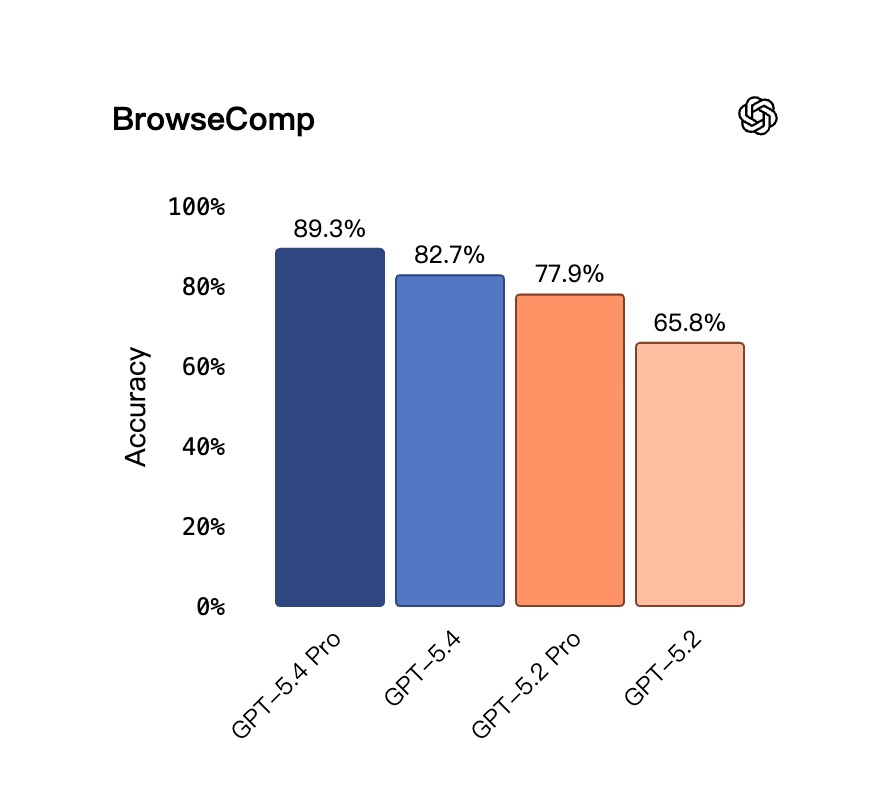
GPT-5.4 是一款自主性更强的「网络搜索捕手」。在 BrowseComp 测试中,对比 GPT-5.2,GPT-5.4 实现了 17% 的绝对值跃升,而 GPT-5.4 Pro 更是以 89.3% 的成绩创下了全新纪录。
BrowseComp:衡量 AI 智能体持续浏览网页、挖掘极难获取信息能力的测试。
在实际体验中这意味着,当你抛出需要从海量网络信息中抽丝剥茧的问题时,GPT-5.4 Thinking 能展现出更强的掌控力。它极具耐心,能跨多轮持续搜寻并锁定最相关的信源。尤其在面对「大海捞针」般的棘手问题时,它能条理清晰地整理信息,最终输出一份逻辑严密、论证清晰的高质量答案。
可控性与操纵感
- 正如 Codex 在开工前会先列出解题思路一样,ChatGPT 中的 GPT-5.4 Thinking 在面对冗长、复杂的指令时,也会先输出一段「前言」,清晰梳理工作计划。更关键的是,你可以在模型「生成回复的中途」,直接追加指令或强行干预思考方向。
这就彻底告别了以往「推倒重来」或「反复追问数十轮」的低效窘境,让你能实时引导模型,精准输出你要的理想答案。
- 此外,在处理硬核任务时,GPT-5.4 能进行更深层次的长时间思考,并对对话早期的每一处细节,都保持着超强的记忆感知。在面对超长工作流或重度提示词时,它能始终维持逻辑一致性,以及内容的高度相关性。
GPT-5.4 使用与定价
从现在起,GPT-5.4 正在 ChatGPT 和 Codex 中逐步推送;在 API 侧,开发者已经可以调用gpt-5.4完成接入,gpt-5.4-pro也已在 API 中同步上线。
- 在 ChatGPT 中,GPT-5.4 Thinking 现已对 Plus、Team 和 Pro 用户开放,正式接棒 GPT-5.2 Thinking。GPT-5.4 Pro 则专属开放给 Pro 与 Enterprise 计划用户。GPT-5.4 Thinking 在 ChatGPT 中的上下文窗口限制,与之前的 GPT-5.2 Thinking 完全保持一致。
GPT-5.2 Thinking 将在 2026 年 6 月 5 日正式退役。
- Codex 中的 GPT-5.4 新增了 1M 上下文窗口的实验性支持。开发者可通过配置
model_context_window和model_auto_compact_token_limit提前尝鲜。
当请求超出标准的 272K 上下文窗口时,超出部分将按正常消耗率的 2 倍计费。
| API 模型 | 输入价格 | 缓存输入价格 | 输出价格 |
|---|---|---|---|
| gpt-5.2 | $1.75/M Token | $0.175 / 100万 Token | $14 / 100万 Token |
| gpt-5.4 | $2.50/M Token | $0.25 / 100万 Token | $15 / 100万 Token |
| gpt-5.2-pro | $21/M Token | – | $168 / 100万 Token |
| gpt-5.4-pro | $30/M Token | – | $180 / 100万 Token |
GPT-5.4 核心能力评估
专业场景
| 测试基准 | GPT-5.4 | GPT-5.4Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2Pro |
|---|---|---|---|---|---|
| GDPval | 83.0% | 82.0% | 70.9% | 70.9% | 74.1% |
| FinanceAgent v1.1 | 56.0% | 61.5% | 54.0% | 59.5% | — |
| Investment Banking Modeling Tasks (Internal) | 87.3% | 83.6% | 79.3% | 68.4% | 71.7% |
| OfficeQA | 68.1% | — | 65.1% | 63.1% | — |
代码编写
| 测试基准 | GPT-5.4 | GPT-5.4Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2Pro |
|---|---|---|---|---|---|
| SWE-Bench Pro | 57.7% | — | 56.8% | 55.6% | — |
| Terminal-Bench 2.0 | 75.1% | — | 77.3% | 62.2% | — |
计算机操作与视觉感知
| 测试基准 | GPT-5.4 | GPT-5.4Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2Pro |
|---|---|---|---|---|---|
| OSWorld-Verified | 75.0% | — | 74.0% | 47.3% | — |
| MMMU Pro(禁用工具) | 81.2% | — | — | 79.5% | — |
| MMMU Pro(启用工具) | 82.1% | — | — | 80.4% | — |
工具调用
| 测试基准 | GPT-5.4 | GPT-5.4Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2Pro |
|---|---|---|---|---|---|
| BrowseComp | 82.7% | 89.3% | 77.3% | 65.8% | 77.9% |
| MCP Atlas | 67.2% | — | — | 60.6% | — |
| Toolathlon | 54.6% | — | 51.9% | 45.7% | — |
| Tau2-bench Telecom | 98.9% | — | — | 98.7% | — |
学术研究
| 测试基准 | GPT-5.4 | GPT-5.4Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2Pro |
|---|---|---|---|---|---|
| Frontier Science Research | 33.0% | 36.7% | — | 25.2% | — |
| FrontierMath(Tier 1–3) | 47.6% | 50.0% | — | 40.7% | — |
| FrontierMath(Tier 4) | 27.1% | 38.0% | — | 18.8% | 31.3% |
| GPQA Diamond | 92.8% | 94.4% | 92.6% | 92.4% | 93.2% |
| Humanity’s Last Exam(禁用工具) | 39.8% | 42.7% | — | 34.5% | 36.6% |
| Humanity’s Last Exam(启用工具) | 52.1% | 58.7% | — | 45.5% | 50.0% |
超长上下文
| 测试基准 | GPT-5.4 | GPT-5.4Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2Pro |
|---|---|---|---|---|---|
| Graphwalks BFS(0K–128K) | 93.0% | — | — | 94.0% | — |
| Graphwalks BFS(256K–1M) | 21.4% | — | — | — | — |
| Graphwalks parents 0–128K(准确率) | 89.8% | — | — | 89.0% | — |
| Graphwalks parents 256K–1M(准确率) | 32.4% | — | — | — | — |
| OpenAI MRCR v2 8-needle 4K–8K | 97.3% | — | — | 98.2% | — |
| OpenAI MRCR v2 8-needle 8K–16K | 91.4% | — | — | 89.3% | — |
| OpenAI MRCR v2 8-needle 16K–32K | 97.2% | — | — | 95.3% | — |
| OpenAI MRCR v2 8-needle 32K–64K | 90.5% | — | — | 92.0% | — |
| OpenAI MRCR v2 8-needle 64K–128K | 86.0% | — | — | 85.6% | — |
| OpenAI MRCR v2 8-needle 128K–256K | 79.3% | — | — | 77.0% | — |
| OpenAI MRCR v2 8-needle 256K–512K | 57.5% | — | — | — | — |
| OpenAI MRCR v2 8-needle 512K–1M | 36.6% | — | — | — | — |
抽象推理
| 测试基准 | GPT-5.4 | GPT-5.4Pro | GPT-5.3-Codex | GPT-5.2 | GPT-5.2Pro |
|---|---|---|---|---|---|
| ARC-AGI-1(Verified) | 93.7% | 94.5% | — | 86.2% | 90.5% |
| ARC-AGI-2(Verified) | 73.3% | 83.3% | — | 52.9% | 54.2%(high) |
无推理干预测试
| 测试基准 | GPT-5.4(无推理) | GPT-5.2(无推理) | GPT-4.1 |
|---|---|---|---|
| OmniDocBench(归一化编辑距离) | 0.109 | 0.140 | — |
| Tau2-bench Telecom | 64.3% | 57.2% | 43.6% |



最新评论
chmod +x之前一定要先把目录cd到安装文件所在的文件夹直接chmod有时不起作用
开dlna后,文件导入真的看不到怎弄
并不完全相同
是不是和KB5077241更新日志重复了