在本文中,我将介绍在 Windows 11 操作系统上安装和使用 WhisperX 的详细步骤。为了方便设置,我选择了使用 Anaconda 虚拟环境,整个过程涉及安装多个关键软件。
WhisperX 是基于 OpenAI 开源项目 Whisper 的一个分支,它是一款功能强大的语音转文本(STT,Speech-to-Text)工具,以其出色的转录能力而闻名,并支持多种语言。更令人兴奋的是,它完全免费。
什么是 Whisper
Whisper 是一个由 OpenAI 开发的通用语音识别模型(ASR),在大量多样化的音频数据集上进行训练,具有惊人的准确性。它同时也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。OpenAI 已经将 Whisper 开源,供社区使用。
为什么选择 WhisperX
Whisper 在大量多样化的音频数据上进行训练。尽管它能够提供高准确度的转录,但相关的时间戳是话语级别而非单词级别,可能存在数秒不准。而且,Whisper 并不原生支持批处理。
WhisperX 提供了一种快速的自动语音识别方法(在使用 large-v2 时可实现 70x 实时速度),具备单词级时间戳和说话者辨识功能。
具体而言:
- 使用 whisper large-v2 进行批处理推断,可实现 70x 实时转录。
- 利用 faster-whisper 作为后端,对于 large-v2 只需小于 8GB 的 GPU 显存。(使用
beam_size=5) - 利用 wav2vec2.0 对齐,实现准确的单词级时间戳。
- 利用来自 pyannote-audio 的说话者辨识,实现多说话者 ASR(带有说话者 ID 标签)。
- VAD 预处理,减少幻听问题,并实现无 WER 降低的批处理。
准备工作
为了简单方便,我使用 Anaconda 虚拟环境进行配置(你也可以使用 Pip)。同时,为了利用 GPU 资源执行程序,需要安装 Nvidia 的 cuBLAS 11.x 和 cuDNN 8.x 库。
环境准备
- Windows 11
- GPU:Nvidia GeForce RTX 系列
- 过墙梯
步骤 1:安装 Git
1在 Git 官网下载 Git for Windows。
2全部按默认配置,一直点击「下一步」安装即可。
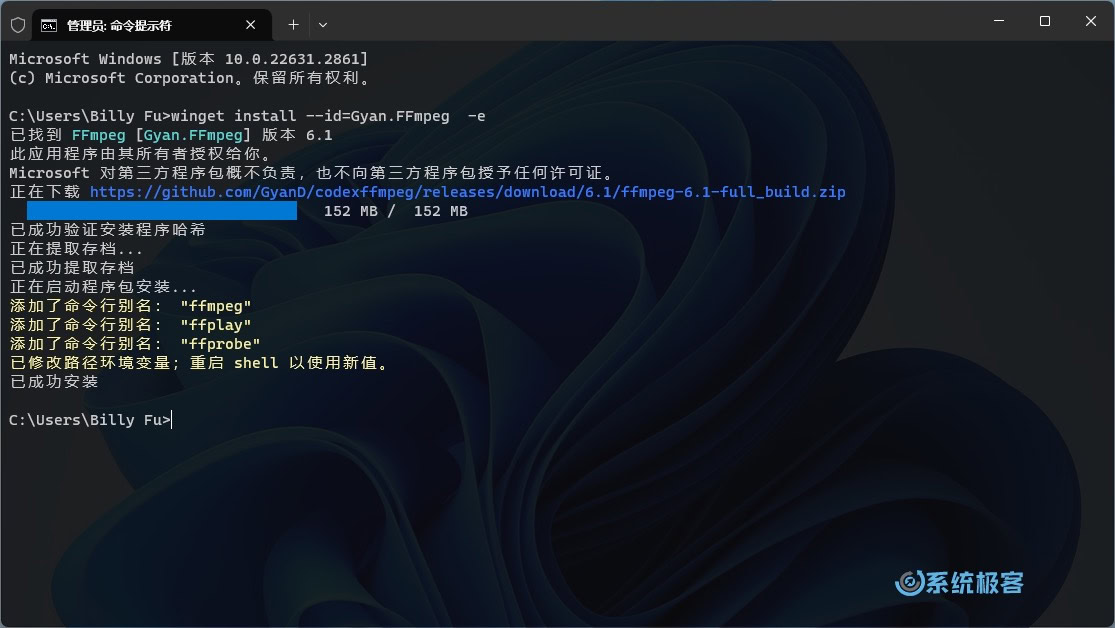
步骤 2:安装 FFmpeg
FFmpeg 是一款免费的多媒体处理软件,主要用于录制、转换和播放视频与音频。在使用 WhisperX 时,它是不可或缺的工具。
在 Windows 11 中,可以使用 winget 包管理器来安装 FFmpeg:
winget install --id=Gyan.FFmpeg -e
步骤 3:安装 CUDA
CUDA 是 Nvidia 开发和提供的通用并行计算平台,专门为图形处理器(GPU)设计。这个平台允许开发者更有效地利用 GPU 的并行计算能力。
在这里要注意的是,最终引入 PyTorch 时,需要考虑其支持的 CUDA 版本(有一些限制)。请访问 https://pytorch.org/get-started/locally/ 进行确认。
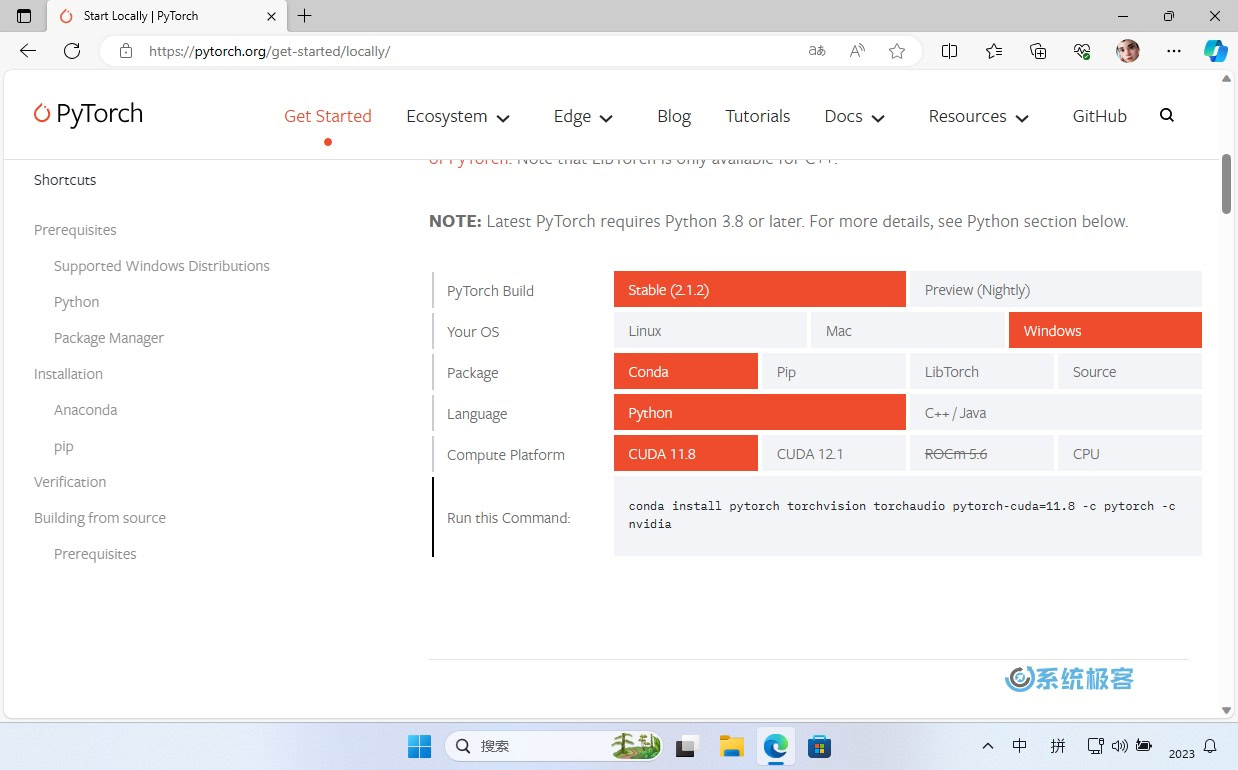
1如果你希望使用 PyTorch 稳定版本,建议使用 CUDA 11.8。可以从 https://developer.nvidia.com/cuda-toolkit-archive 下载相应的存档文件。
2运行安装程序时,会有各种选项,按默认配置一路「下一步」即可。
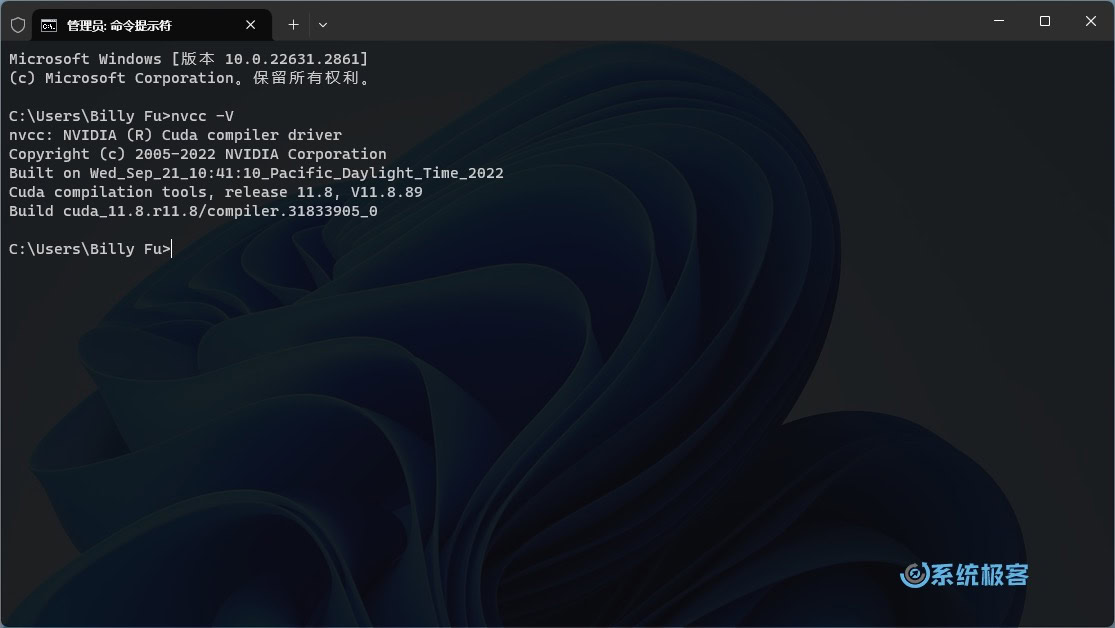
3安装完成后,在 Windows 的「命令提示符中」,执行以下命令验证安装。
nvcc -V
步骤 4:导入 cuDNN
cuDNN 是一款在 Nvidia CUDA 工具包上运行的深度学习库。它专为加速深度学习任务而设计,提供了在 GPU 上高效执行深度神经网络所需的各种功能和优化。
1下载 cuDNN。(在登录 Nvidia 账户后,需要注册成为 Nvidia Developer Program 会员。在这个过程中,会要求提供个人信息。)
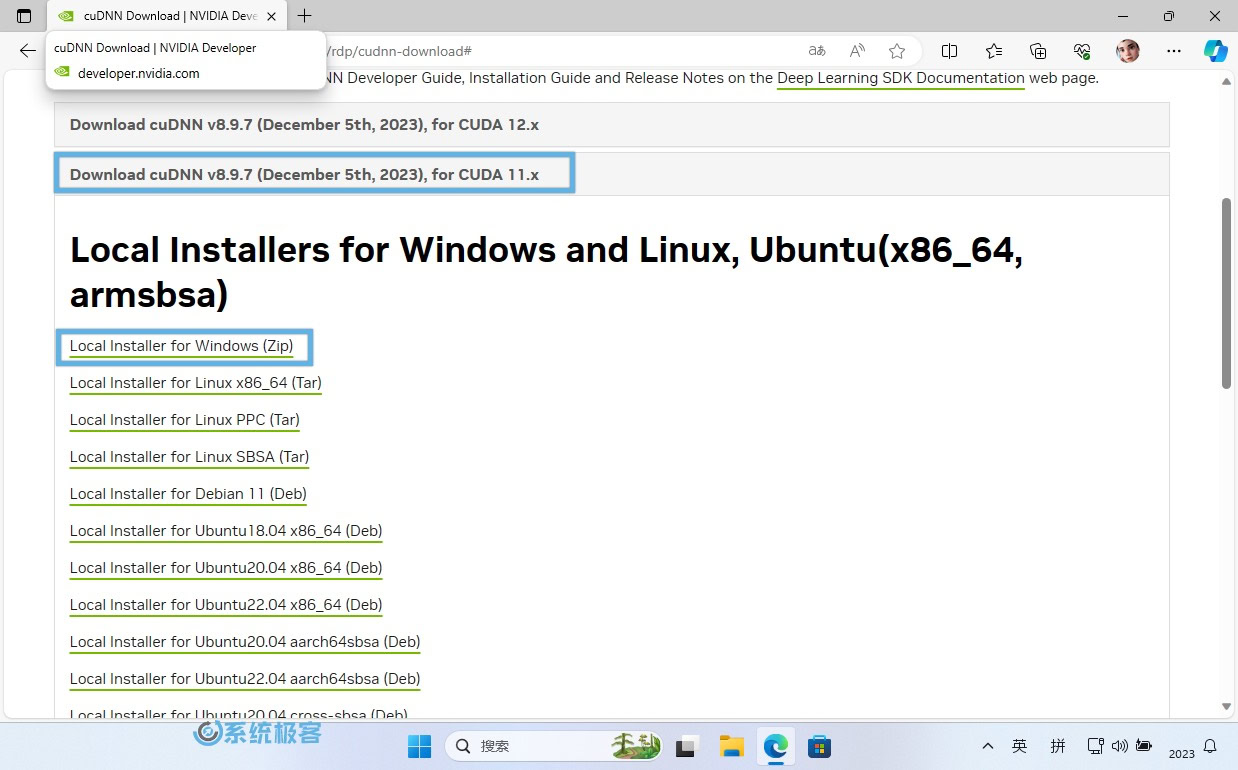
2选择CUDA 11.x版本。
3选择Local Installer for Windows(Zip)下载。
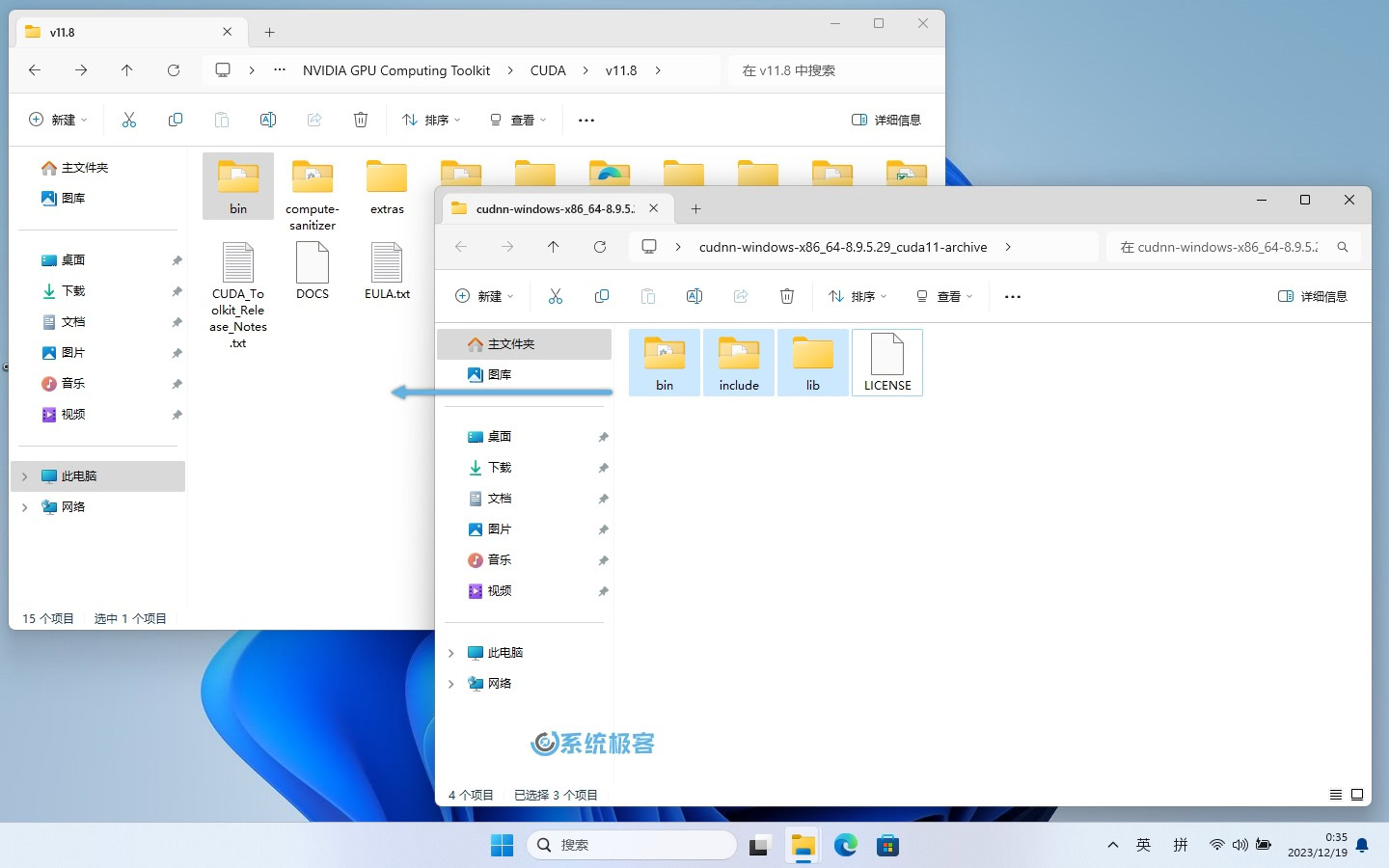
4将下载好的 zip 文件解压出来,会得到如下 3 个文件夹:
- bin
- include
- lib
- LICENSE 是许可文件,可以无视。
5将上述 3 个文件夹移动到CUDA\v11.8目录中,路径为:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8
在CUDA\v1.8文件夹中,虽然有相同的目录,但没有相同的文件,所以不会覆盖。可以直接进行拖放操作。
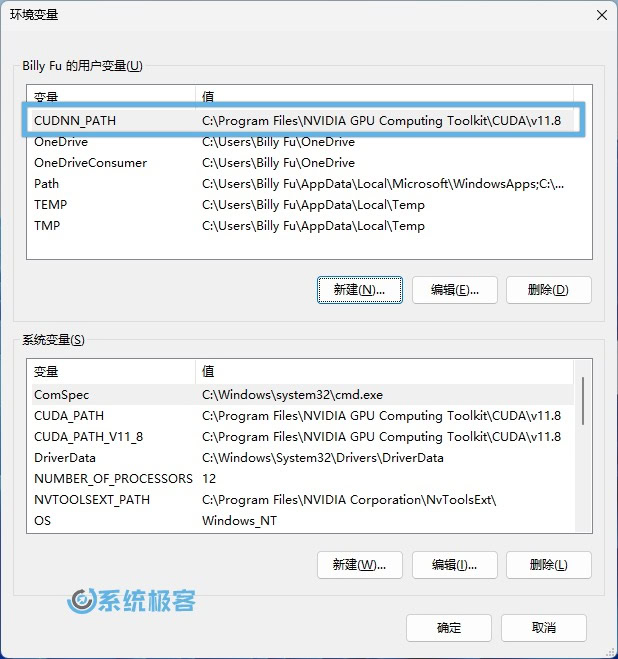
6使用Windows + R快捷键打开「运行」,输出以下命令,然后按Ctrl + Shift + Enter以管理员权限启动「环境变量」。
C:\Windows\system32\rundll32.exe sysdm.cpl, EditEnvironmentVariables
7添加以下环境变量:
- 变量名:
CUDNN_PATH - 变量值:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8
开始安装 WhisperX
步骤 1:安装 Conda 包管理器
Anaconda 包含了许多常用的科学计算包,我们通过它在 Windows 上安装 Conda 包管理器:
2还是按默认选项一路「下一步」完成安装。
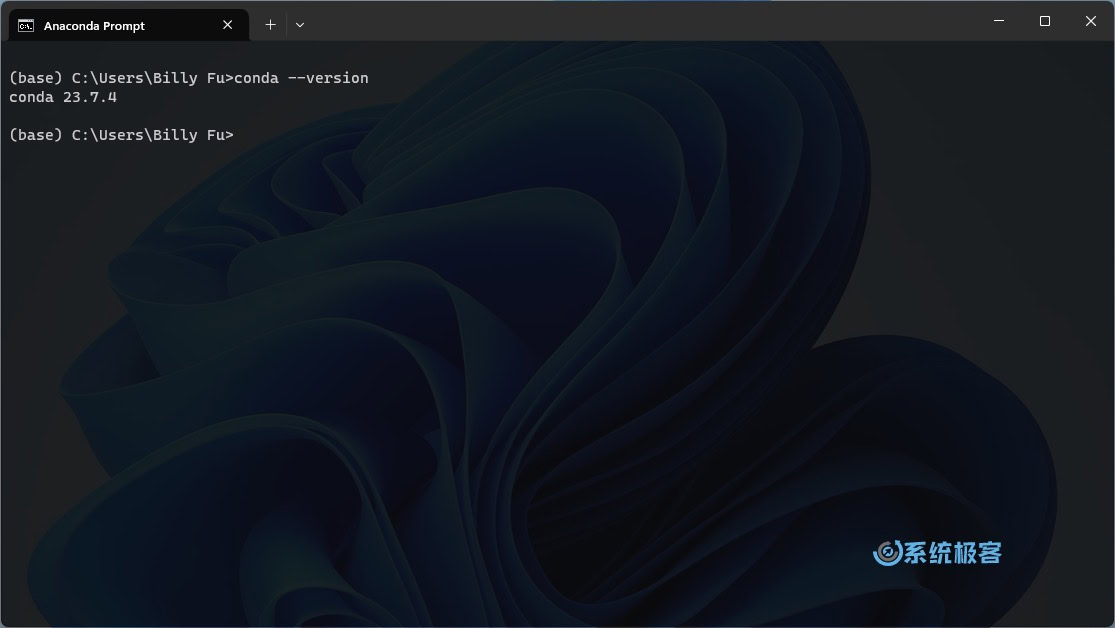
3在「开始」菜单中打开 Anaconda Prompt,然后在命令行中输入以下命令验证 Conda 是否正确安装:
conda --version
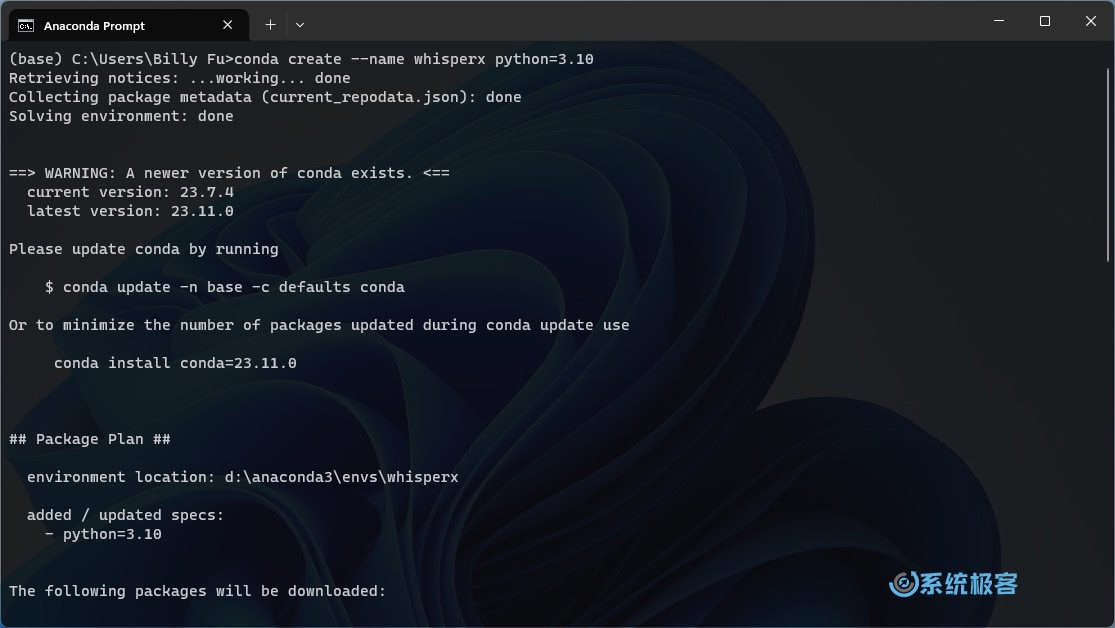
步骤 2:配置 WhisperX 虚拟环境
打开 Anaconda Prompt 命令行窗口,运行以下命令创建一个名为whisperx的虚拟环境,并指定要安装的 Python版本(官方推荐 Python 3.10):
conda create --name whisperx python=3.10
步骤 3:激活 WhisperX 虚拟环境:
执行以下命令激活刚刚创建的虚拟环境:
conda activate whisperx
步骤 4:安装 PyTorch 库等依赖包
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
步骤 5:使用 pip 安装/升级 WhisperX 仓库
- 安装
pip install git+https://github.com/m-bain/whisperx.git
- 升级软件包
pip install git+https://github.com/m-bain/whisperx.git --upgrade
使用 WhisperX
激活 WhisperX 虚拟环境
打开 Anaconda Prompt,激活 WhisperX 虚拟环境:
conda activate whisperx
默认参数
导航到包含音频或视频文件的文件夹,使用默认参数(small)执行命令:
whisperx examples/sample01.wav
选择模型和语言
WhisperX 提供不同的模型,通常较大的模型提供更高的质量,但需要性能强大的 GPU。你可以使用--model参数指定模型。此外,WhisperX 可以自动检测语言,也可以使用--language参数指定语言。
whisperx video.mp4 --model large-v3 --language en
为了减少 GPU 显存需求,可以尝试以下任一方法(后两项可能影响转录质量):
- 减小批处理大小,例如
-batch_size 4 - 使用较小的 ASR 模型
-model base - 使用较轻的计算类型
-compute_type int8
要启用说话人分离功能,请在--hf_token参数后附上你在 Hugging Face 的 Access Token ,可以在这里生成,并接受以下模型的用户协议:Segmentation 和 Speaker-Diarization-3.1(如果选择使用 Speaker-Diarization 2.x,请按照这里的要求进行操作)。
Whisper 模型专门用于语音识别和翻译任务,能够将语音音频转换为其所在语言的文本(ASR),同时还可以进行英语翻译(语音翻译)。OpenAI 的研究人员开发这些模型,旨在研究在大规模弱监督下训练的语音处理系统的鲁棒性。总共有 9 个不同大小和能力的模型,具体情况请参见下表:
| 模型大小 | 参数数量(M 百万) | 仅英文模型 | 多语言模型 | 所需 VRAM | 相对速度 |
|---|---|---|---|---|---|
| tiny | 39 M | ✅ | ✅ | 约 1 GB | ~32x |
| base | 74 M | ✅ | ✅ | 约 1 GB | ~16x |
| small | 244 M | ✅ | ✅ | 约 2 GB | ~6x |
| medium | 769 M | ✅ | ✅ | 约 5 GB | ~2x |
| large | 1550 M | N/A | ✅ | 约 10 GB | 1x |
于 2022 年 12 月,推出了一款升级版的大型模型large-v2,并于 2023 年 11 月发布了large-v3。
其它参数
你可以摸索各种命令行参数,定制自己的 WhisperX 体验。使用whisperx --help可以查看可用参数及描述列表。
更多用法请参考 WhisperX、faster-whisper 和 whisper 的 Github 页面。
总的来说,WhisperX 是一款基于 OpenAI 开源项目 Whisper 的分支工具,除了转录和翻译音频外,还提供单词级时间戳和说话者辨识功能。无论你是在不同语言中转录,选择特定模型,还是自定义设置,WhisperX 都提供了更为灵活的强大解决方案。




最新评论
你当前登录的用户不是管理员账户(没在administrators组中)?
奇怪,为啥我已经右键以管理员运行uup_download_windows了cmd里还提示我需要管理员权限运行
valeo@DESKTOP-BHEH91Q:~$ sudo systemctl is-active docker System has not been booted with systemd as init system (PID 1). Can't operate. Failed to connect to bus: Host is down 这个问题怎么解呀各路大神
Win11更改任务栏为顶部,把03改成01操作后没变化,在此操作发现注册表又还原回为03。 也就是说改注册表也是改不了,不知道为什么WIN11要把这个功能去掉,又影响了什么,一个系统升级改来改去。