
Qwen3.5 正式发布 ,并推出该系列首款模型 Qwen3.5-397B-A17B 的开放权重版本。作为原生「视觉-语言」模型,Qwen3.5-397B-A17B 在推理、编程、智能体能力和多模态理解等全维度基准测试中表现优异,可显著提升开发者与企业的生产效率。
- 该模型采用了创新混合架构,将线性注意力(Gated Delta Networks)与稀疏混合专家(MoE)相结合,实现了出众的推理效率。
- 模型总参数量达 3970 亿,每次前向传播仅激活 170 亿参数,在完整保留核心能力的同时,实现了速度与使用成本的双重优化。
- 阿里还将模型的语言与方言支持范围,从 119 种扩展到了 201 种,为全球用户带来更广泛的适配能力与更完善的使用支持。
Qwen3.5-Plus 为该模型的 API 版本,可以通过阿里云百炼获取服务:
- 官方工具及自适应调用
- 1M token 上下文窗口
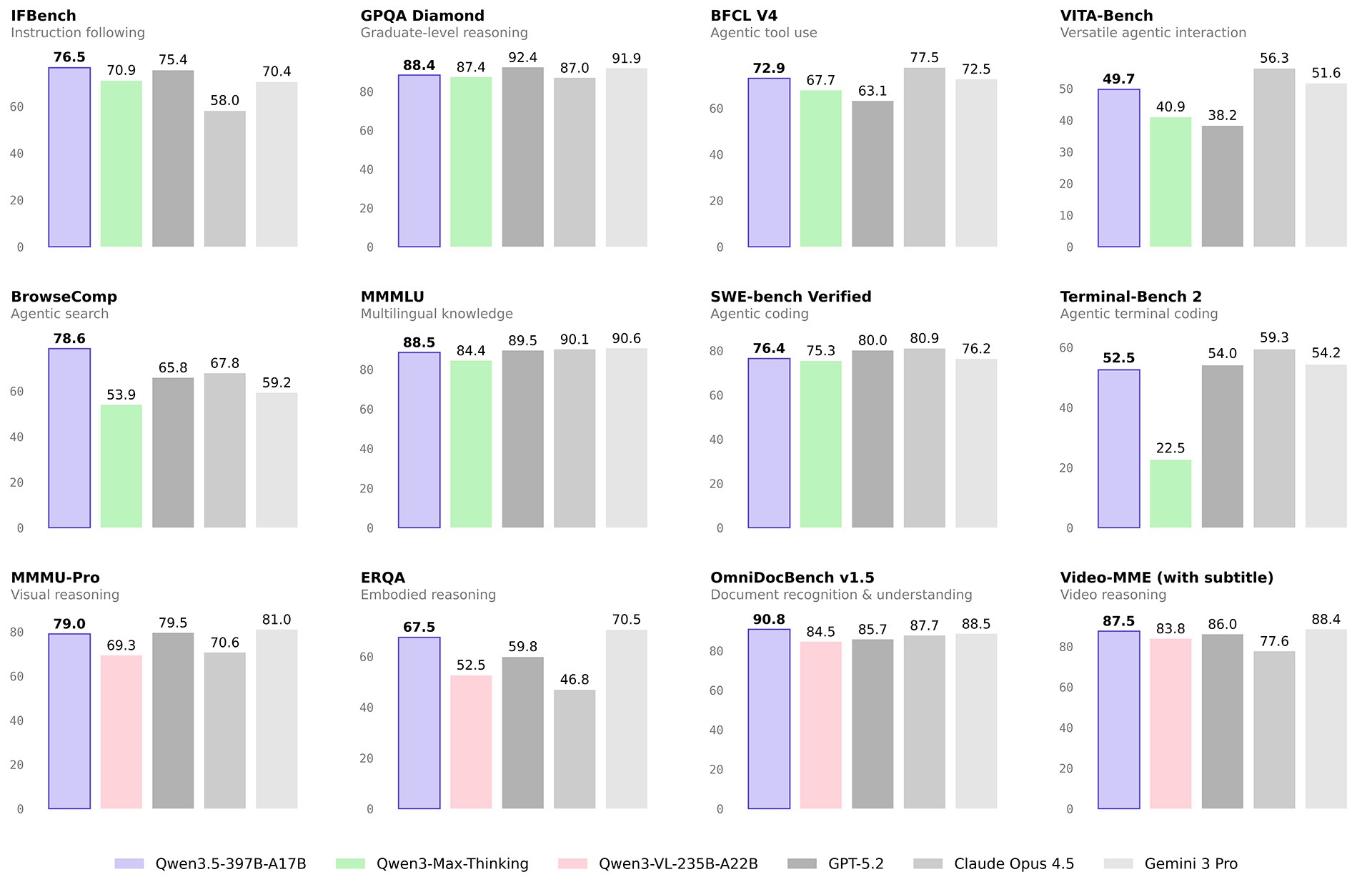
模型表现
模型l团队在多类评估任务与模态下,将 Qwen3.5 与同期前沿模型展开了全面的对比测试。
自然语言
| GPT5.2 | Claude 4.5 Opus | Gemini-3 Pro | Qwen3-Max-Thinking | K2.5-1T-A32B | Qwen3.5-397B-A17B | |
|---|---|---|---|---|---|---|
| Knowledge | ||||||
| MMLU-Pro | 87.4 | 89.5 | 89.8 | 85.7 | 87.1 | 87.8 |
| MMLU-Redux | 95.0 | 95.6 | 95.9 | 92.8 | 94.5 | 94.9 |
| SuperGPQA | 67.9 | 70.6 | 74.0 | 67.3 | 69.2 | 70.4 |
| C-Eval | 90.5 | 92.2 | 93.4 | 93.7 | 94.0 | 93.0 |
| Instruction Following | ||||||
| IFEval | 94.8 | 90.9 | 93.5 | 93.4 | 93.9 | 92.6 |
| IFBench | 75.4 | 58.0 | 70.4 | 70.9 | 70.2 | 76.5 |
| MultiChallenge | 57.9 | 54.2 | 64.2 | 63.3 | 62.7 | 67.6 |
| Long Context | ||||||
| AA-LCR | 72.7 | 74.0 | 70.7 | 68.7 | 70.0 | 68.7 |
| LongBench v2 | 54.5 | 64.4 | 68.2 | 60.6 | 61.0 | 63.2 |
| STEM | ||||||
| GPQA | 92.4 | 87.0 | 91.9 | 87.4 | 87.6 | 88.4 |
| HLE | 35.5 | 30.8 | 37.5 | 30.2 | 30.1 | 28.7 |
| HLE-Verified | 43.3 | 38.8 | 48 | 37.6 | — | 37.6 |
| Reasoning | ||||||
| LiveCodeBench v6 | 87.7 | 84.8 | 90.7 | 85.9 | 85.0 | 83.6 |
| HMMT Feb 25 | 99.4 | 92.9 | 97.3 | 98.0 | 95.4 | 94.8 |
| HMMT Nov 25 | 100 | 93.3 | 93.3 | 94.7 | 91.1 | 92.7 |
| IMOAnswerBench | 86.3 | 84.0 | 83.3 | 83.9 | 81.8 | 80.9 |
| AIME26 | 96.7 | 93.3 | 90.6 | 93.3 | 93.3 | 91.3 |
| General Agent | ||||||
| BFCL-V4 | 63.1 | 77.5 | 72.5 | 67.7 | 68.3 | 72.9 |
| TAU2-Bench | 87.1 | 91.6 | 85.4 | 84.6 | 77.0 | 86.7 |
| VITA-Bench | 38.2 | 56.3 | 51.6 | 40.9 | 41.9 | 49.7 |
| DeepPlanning | 44.6 | 33.9 | 23.3 | 28.7 | 14.5 | 34.3 |
| Tool Decathlon | 43.8 | 43.5 | 36.4 | 18.8 | 27.8 | 38.3 |
| MCP-Mark | 57.5 | 42.3 | 53.9 | 33.5 | 29.5 | 46.1 |
| Search Agent | ||||||
| HLE w/ tool | 45.5 | 43.4 | 45.8 | 49.8 | 50.2 | 48.3 |
| BrowseComp | 65.8 | 67.8 | 59.2 | 53.9 | –/74.9 | 69.0/78.6 |
| BrowseComp-zh | 76.1 | 62.4 | 66.8 | 60.9 | — | 70.3 |
| WideSearch | 76.8 | 76.4 | 68.0 | 57.9 | 72.7 | 74.0 |
| Seal-0 | 45.0 | 47.7 | 45.5 | 46.9 | 57.4 | 46.9 |
| Multilingualism | ||||||
| MMMLU | 89.5 | 90.1 | 90.6 | 84.4 | 86.0 | 88.5 |
| MMLU-ProX | 83.7 | 85.7 | 87.7 | 78.5 | 82.3 | 84.7 |
| NOVA-63 | 54.6 | 56.7 | 56.7 | 54.2 | 56.0 | 59.1 |
| INCLUDE | 87.5 | 86.2 | 90.5 | 82.3 | 83.3 | 85.6 |
| Global PIQA | 90.9 | 91.6 | 93.2 | 86.0 | 89.3 | 89.8 |
| PolyMATH | 62.5 | 79.0 | 81.6 | 64.7 | 43.1 | 73.3 |
| WMT24++ | 78.8 | 79.7 | 80.7 | 77.6 | 77.6 | 78.9 |
| MAXIFE | 88.4 | 79.2 | 87.5 | 84.0 | 72.8 | 88.2 |
| Coding Agent | ||||||
| SWE-bench Verified | 80.0 | 80.9 | 76.2 | 75.3 | 76.8 | 76.4 |
| SWE-bench Multilingual | 72.0 | 77.5 | 65.0 | 66.7 | 73.0 | 69.3 |
| SecCodeBench | 68.7 | 68.6 | 62.4 | 57.5 | 61.3 | 68.3 |
| Terminal Bench 2 | 54.0 | 59.3 | 54.2 | 22.5 | 50.8 | 52.5 |
视觉语言
| GPT5.2 | Claude 4.5 Opus | Gemini-3 Pro | Qwen3-VL-235B-A22B | K2.5-1T-A32B | Qwen3.5-397B-A17B | |
|---|---|---|---|---|---|---|
| STEM and Puzzle | ||||||
| MMMU | 86.7 | 80.7 | 87.2 | 80.6 | 84.3 | 85.0 |
| MMMU-Pro | 79.5 | 70.6 | 81.0 | 69.3 | 78.5 | 79.0 |
| MathVision | 83.0 | 74.3 | 86.6 | 74.6 | 84.2 | 88.6 |
| Mathvista(mini) | 83.1 | 80.0 | 87.9 | 85.8 | 90.1 | 90.3 |
| We-Math | 79.0 | 70.0 | 86.9 | 74.8 | 84.7 | 87.9 |
| DynaMath | 86.8 | 79.7 | 85.1 | 82.8 | 84.4 | 86.3 |
| ZEROBench | 9 | 3 | 10 | 4 | 9 | 12 |
| ZEROBench_sub | 33.2 | 28.4 | 39.0 | 28.4 | 33.5 | 41.0 |
| BabyVision | 34.4 | 14.2 | 49.7 | 22.2 | 36.5 | 52.3/43.3 |
| General VQA | ||||||
| RealWorldQA | 83.3 | 77.0 | 83.3 | 81.3 | 81.0 | 83.9 |
| MMStar | 77.1 | 73.2 | 83.1 | 78.7 | 80.5 | 83.8 |
| HallusionBench | 65.2 | 64.1 | 68.6 | 66.7 | 69.8 | 71.4 |
| MMBenchEN-DEV-v1.1 | 88.2 | 89.2 | 93.7 | 89.7 | 94.2 | 93.7 |
| SimpleVQA | 55.8 | 65.7 | 73.2 | 61.3 | 71.2 | 67.1 |
| Text Recognition and Document Understanding | ||||||
| OmniDocBench1.5 | 85.7 | 87.7 | 88.5 | 84.5 | 88.8 | 90.8 |
| CharXiv(RQ) | 82.1 | 68.5 | 81.4 | 66.1 | 77.5 | 80.8 |
| MMLongBench-Doc | — | 61.9 | 60.5 | 56.2 | 58.5 | 61.5 |
| CC-OCR | 70.3 | 76.9 | 79.0 | 81.5 | 79.7 | 82.0 |
| AI2D_TEST | 92.2 | 87.7 | 94.1 | 89.2 | 90.8 | 93.9 |
| OCRBench | 80.7 | 85.8 | 90.4 | 87.5 | 92.3 | 93.1 |
| Spatial Intelligence | ||||||
| ERQA | 59.8 | 46.8 | 70.5 | 52.5 | — | 67.5 |
| CountBench | 91.9 | 90.6 | 97.3 | 93.7 | 94.1 | 97.2 |
| RefCOCO(avg) | — | — | 84.1 | 91.1 | 87.8 | 92.3 |
| ODInW13 | — | — | 46.3 | 43.2 | — | 47.0 |
| EmbSpatialBench | 81.3 | 75.7 | 61.2 | 84.3 | 77.4 | 84.5 |
| RefSpatialBench | — | — | 65.5 | 69.9 | — | 73.6 |
| LingoQA | 68.8 | 78.8 | 72.8 | 66.8 | 68.2 | 81.6 |
| V* | 75.9 | 67.0 | 88.0 | 85.9 | 77.0 | 95.8/91.1 |
| Hypersim | — | — | — | 11.0 | — | 12.5 |
| SUNRGBD | — | — | — | 34.9 | — | 38.3 |
| Nuscene | — | — | — | 13.9 | — | 16.0 |
| Video Understanding | ||||||
| VideoMME(w sub.) | 86 | 77.6 | 88.4 | 83.8 | 87.4 | 87.5 |
| VideoMME(w/o sub.) | 85.8 | 81.4 | 87.7 | 79.0 | 83.2 | 83.7 |
| VideoMMMU | 85.9 | 84.4 | 87.6 | 80.0 | 86.6 | 84.7 |
| MLVU (M-Avg) | 85.6 | 81.7 | 83.0 | 83.8 | 85.0 | 86.7 |
| MVBench | 78.1 | 67.2 | 74.1 | 75.2 | 73.5 | 77.6 |
| LVBench | 73.7 | 57.3 | 76.2 | 63.6 | 75.9 | 75.5 |
| MMVU | 80.8 | 77.3 | 77.5 | 71.1 | 80.4 | 75.4 |
| Visual Agent | ||||||
| ScreenSpot Pro | — | 45.7 | 72.7 | 62.0 | — | 65.6 |
| OSWorld-Verified | 38.2 | 66.3 | — | 38.1 | 63.3 | 62.2 |
| AndroidWorld | — | — | — | 63.7 | — | 66.8 |
| Medical VQA | ||||||
| SLAKE | 76.9 | 76.4 | 81.3 | 54.7 | 81.6 | 79.9 |
| PMC-VQA | 58.9 | 59.9 | 62.3 | 41.2 | 63.3 | 64.2 |
| MedXpertQA-MM | 73.3 | 63.6 | 76.0 | 47.6 | 65.3 | 70.0 |
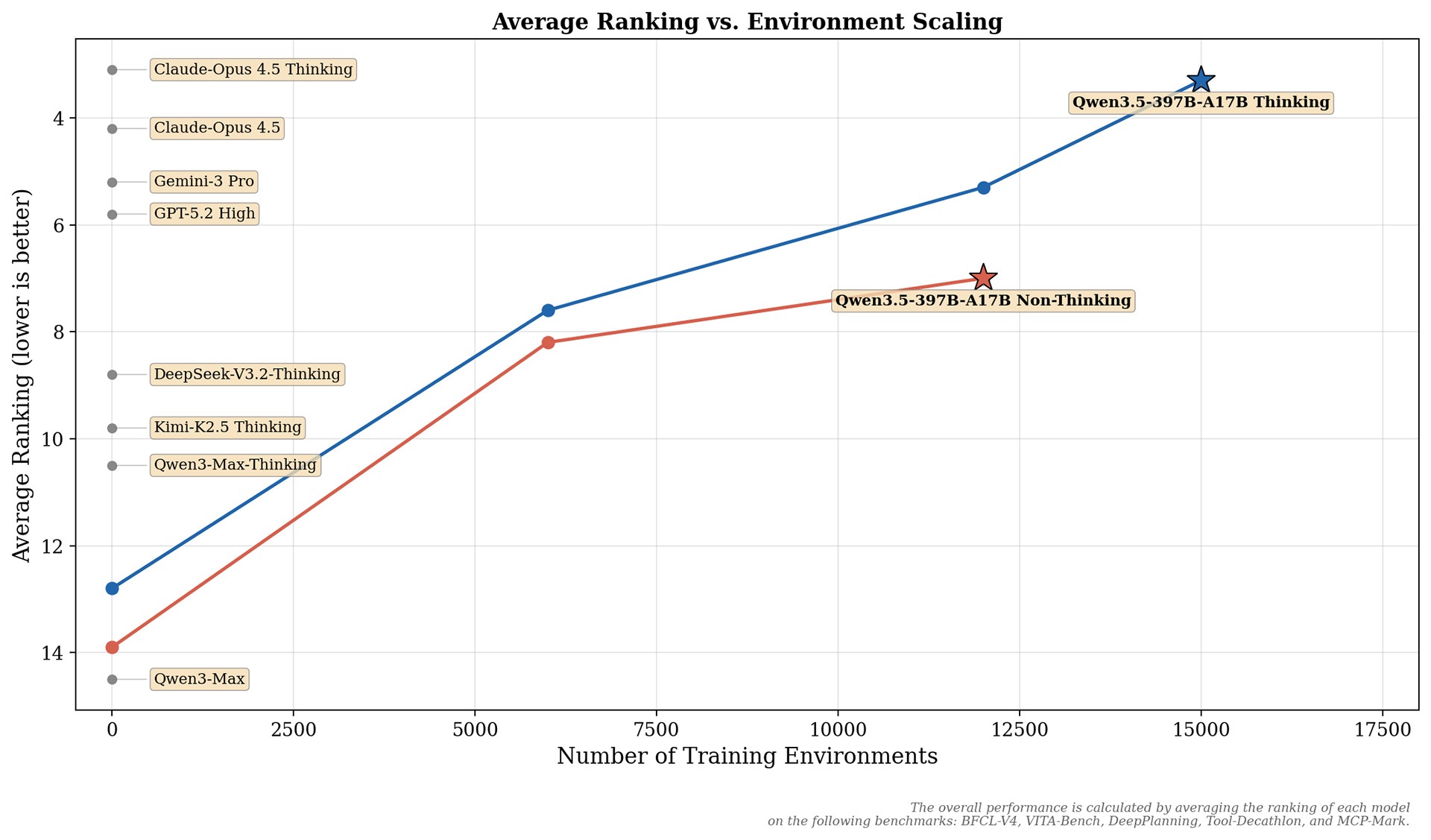
相较于 Qwen3 系列模型,Qwen3.5 的 Post-training 性能提升,主要来自对各类 RL 任务和环境的全面扩展。并且更侧重 RL 环境的难度与可泛化性,而非针对特定指标、或是窄范围类别的 query 做定向优化。
下图展示了在通用 Agent 能力上,模型效果随 RL Environment scaling 带来的性能增益。模型整体性能,由各模型在以下基准测试中的平均排名计算得出:BFCL-V4、VITA-Bench、DeepPlanning、Tool-Decathlon 和 MCP-Mark。更多任务的 scaling 效果。
预训练
Qwen3.5 在能力、效率与通用性三大维度上,全面推进了预训练技术的迭代:
- 能力:模型在更大规模的「视觉-文本」语料上完成训练,同时强化了中英文、多语言、STEM 与推理相关数据,并采用了更严格的数据过滤标准。最终实现了跨代性能持平:Qwen3.5-397B-A17B 的表现,与参数量超 1T 的 Qwen3-Max-Base 相当。
- 效率:模型基于 Qwen3-Next 架构打造,核心升级包括:更高稀疏度的 MoE、Gated DeltaNet + Gated Attention 混合注意力机制、稳定性优化,以及多 token 预测能力。在 32k/256k 上下文长度下,Qwen3.5-397B-A17B 的解码吞吐量,分别达到 Qwen3-Max 的 8.6 倍与 19.0 倍,同时保持了相当的性能表现。同上下文长度下,Qwen3.5-397B-A17B 的解码吞吐量,也分别达到 Qwen3-235B-A22B 的 3.5 倍与 7.2 倍。
- 通用性:模型通过早期「文本-视觉」融合技术,搭配扩展后的视觉、STEM、视频相关数据,实现了原生多模态能力,在相近参数量规模下,性能要优于 Qwen3-VL。模型的多语言覆盖范围,也从 119 种提升到了 201 种「语言 + 方言」;词表规模从 15 万升级到了 25 万,在多数语言上可带来约 10–60% 的编码/解码效率提升。

以下是基座模型的性能表现。
| Qwen3-235B-A22B | GLM-4.5-355B-A32B | DeepSeeK-V3.2-671B-A37B | K2-1T-A32B | Qwen3.5-397B-A17B | |
|---|---|---|---|---|---|
| General Knowledge & Multilingual | |||||
| MMLU | 87.33 | 86.56 | 88.11 | 87.38 | 88.61 |
| MMLU-Pro | 67.73 | 65.00 | 62.82 | 67.64 | 76.01 |
| MMLU-Redux | 87.44 | 86.86 | 87.29 | 86.65 | 89.09 |
| SuperGPQA | 42.84 | 44.56 | 43.46 | 44.86 | 57.96 |
| C-Eval | 91.82 | 85.50 | 90.48 | 91.82 | 91.82 |
| MMMLU | 81.27 | 82.26 | 83.20 | 82.26 | 85.82 |
| Include | 75.26 | 73.41 | 76.52 | 72.05 | 79.27 |
| Nova | 66.52 | 60.96 | 60.40 | 61.44 | 67.55 |
| Reasoning & STEM | |||||
| BBH | 87.95 | 87.68 | 86.03 | 89.11 | 90.98 |
| KoRBench | 50.80 | 52.80 | 54.00 | 53.84 | 54.08 |
| GPQA | 47.47 | 44.63 | 44.16 | 46.78 | 54.64 |
| MATH | 71.84 | 61.84 | 64.40 | 71.50 | 74.14 |
| GSM8K | 91.17 | 89.31 | 89.12 | 92.12 | 93.71 |
| Coding | |||||
| Evalplus | 77.60 | 69.49 | 62.68 | 71.77 | 79.32 |
| MultiPLE | 65.94 | 62.51 | 61.88 | 70.64 | 79.39 |
| SWE-agentless | 31.77 | 29.23 | 34.67 | 28.54 | 43.26 |
| CRUX-I | 64.25 | 67.63 | 63.25 | 70.50 | 71.13 |
| CRUX-O | 78.88 | 77.13 | 73.88 | 77.13 | 82.38 |
基础设施
Qwen3.5 依托异构基础设施,实现了高效的原生多模态训练:
- 在视觉与语言组件上采用解耦并行策略,规避了统一方案带来的效率损耗。通过稀疏激活技术,实现了跨模块计算重叠,在混合「文本-图像-视频」数据的训练场景下,相较纯文本基线实现了近 100% 的训练吞吐。
- 在此基础上,原生 FP8 流水线对激活、MoE 路由与 GEMM 运算采用低精度计算,同时通过运行时监控,在敏感层保留 BF16 精度。这套方案实现了约 50% 的激活显存占用降低,以及超 10% 的训练加速,且可稳定扩展至数万亿 token 规模。
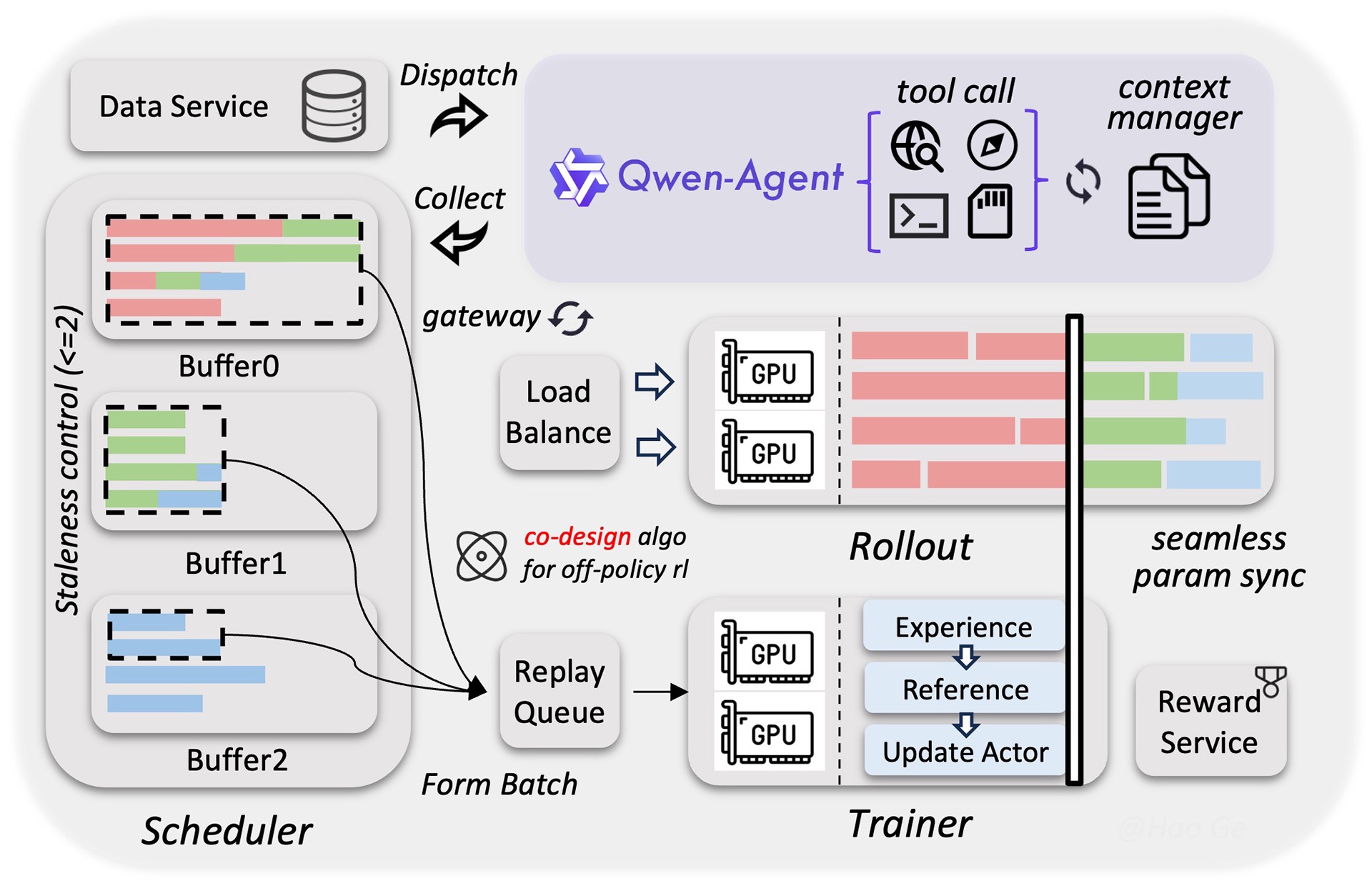
为持续释放强化学习的潜力,团队搭建了可扩展的异步强化学习框架。该框架完整支持 Qwen3.5 全尺寸模型,可全面覆盖文本、多模态及多轮交互场景。
- 依托训推分离架构的解耦式设计,该框架大幅提升了硬件利用率,同时实现了动态负载均衡与细粒度故障恢复。配合 FP8 训推、Rollout 路由回放、投机采样以及多轮 Rollout 锁定等技术,进一步优化了系统吞吐,提升了训推一致性。
- 通过系统与算法的协同设计,该框架在严格控制样本陈旧性的基础上,有效缓解了数据长尾问题,提升了训练曲线的稳定性与模型性能上限。此外,该框架面向原生智能体工作流设计,可实现稳定、无缝的多轮环境交互,彻底消除了框架层的调度中断问题。
这套解耦设计,让系统可扩展至百万级规模的 Agent 脚手架与环境,进而显著增强了模型的泛化能力。上述一系列优化,最终实现了 3×–5× 的端到端加速,展现出卓越的稳定性、运行效率与可扩展性。
开始使用 Qwen3.5
与 Qwen3.5 交互
你可以前往 Qwen Chat 体验 Qwen3.5。官网为用户提供了「自动(auto)」「思考(thinking)」「快速(fast)」三种使用模式:
- 「自动」模式:你可以启用自适应思考能力,同时调用搜索、代码解释器等工具;
- 「思考」模式:模型会针对复杂问题进行深度思考;
- 「快速」模式:模型将直接输出回答,不消耗思考 token。
阿里云百炼
你还可以通过阿里云百炼,调用旗舰模型 Qwen3.5-Plus 进行体验。若需开启推理、联网搜索与 Code Interpreter 等高级能力,只需传入以下参数:
enable_thinking:开启推理模式(链式思考)enable_search:开启联网搜索与 Code Interpreter



最新评论
edge取消云母后,谷歌接上来了,巨硬作为第一方丢脸不
可以,退回一个旧版本就好了。windows兼容的问题。旧版本退出账户后才能显示搜索页。具体参见:https://learn.microsoft.com/zh-cn/answers/questions/5772333/microsoft-store-microsoft-store
电脑睡眠后出现灰屏(不亮也不黑),也不能唤醒,是什么原因,如何解决?
淘宝、csdn,这些网站一个个的都想扫描内网是干嘛