Fun-ASR-Nano-2512 语音识别大模型开源!这是通义实验室倾力打造的端到端语音识别大模型,它历经了数千万小时真实语音数据的深度打磨,具备卓越的上下文理解能力和广泛的行业适应性。
该模型不仅支持低延迟的实时听写,还广泛覆盖了 31 种语言。无论是在教育还是金融等垂直领域,它都能精准捕捉专业术语和行业惯用表达,有效抑制「幻觉」生成,并攻克了语种混淆的难题,真正做到了「听得清、懂其意、写得准」。
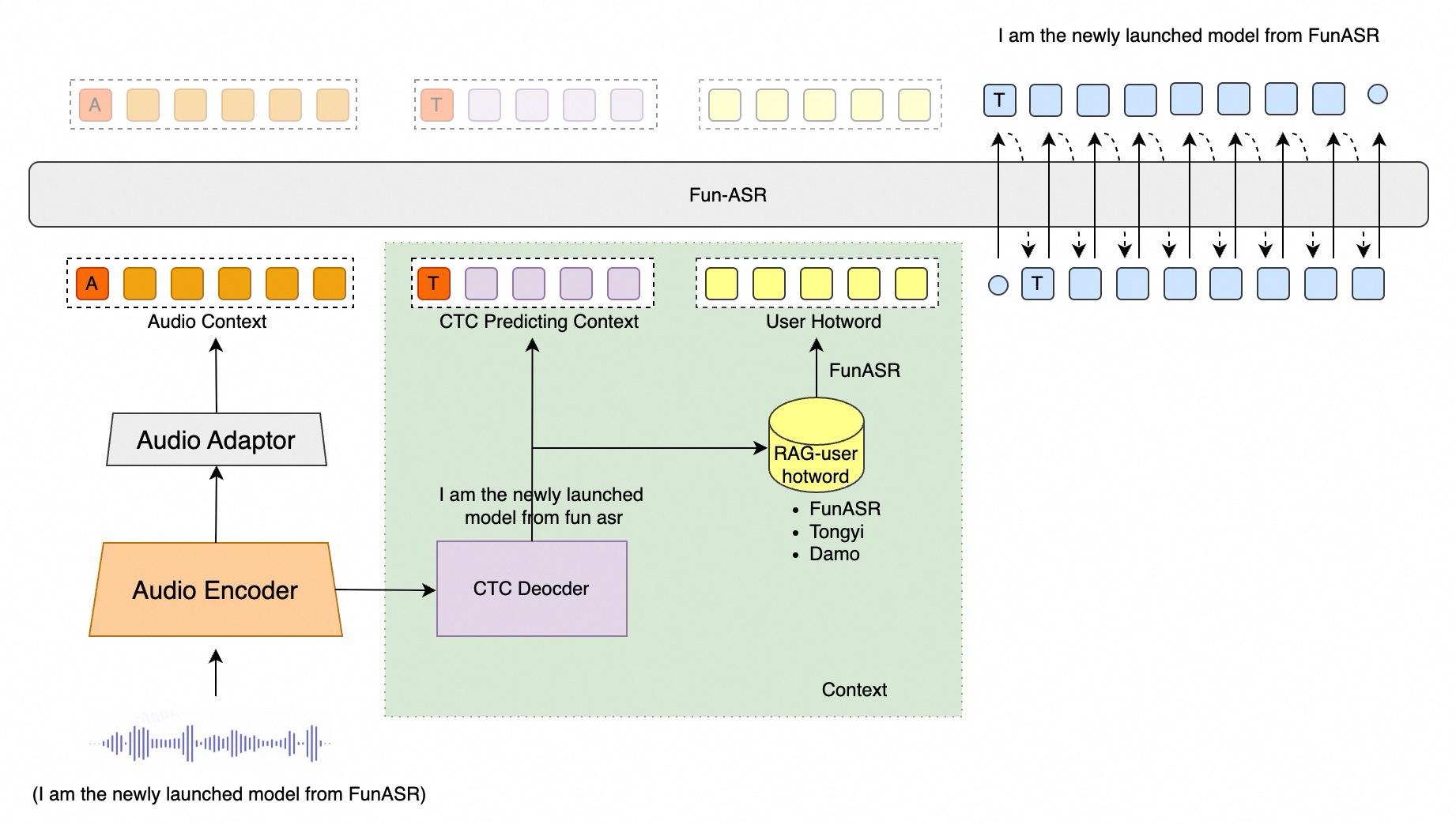
Fun-ASR-Nano-2512
此次开源的 Fun-ASR-Nano-2512(0.8B)是一款基于海量真实语音数据训练的端到端语音识别大模型。它在保持轻量化的同时,支持极低延迟的实时转写,并原生支持 31 种语言的识别能力。
核心特性
Fun-ASR 专注于解决高精度语音识别、多语言支持以及行业深度定制的核心需求:
- 无惧远场与高噪挑战:针对会议室、车载座舱、工业现场等复杂的远距离拾音及高噪声场景,模型进行了深度专项优化,识别准确率高达 93%。
- 精通方言与地方口音:
- 7 大方言:全面支持吴语、粤语、闽语、客家话、赣语、湘语和晋语。
- 26 种地方口音:覆盖河南、陕西、湖北、四川、重庆、云南、贵州、广东和广西等 20 多个地区的特定口音,旨在打破地域沟通壁垒。
- 多语言「自由说」:支持 31 种语言的流畅识别,重点对东亚/东南亚语种进行了定向调优,能完美应对语种自由切换与混合识别的复杂场景。
- 音乐背景下的歌词捕获:强化了在音乐背景干扰下的语音提取性能,不仅能有效「抗噪」,更能对歌曲中的歌词内容实现精准识别。
Fun-ASR 模型体验
- 模型仓库:魔搭社区、huggingface
- 在线体验:魔搭社区创空间


最新评论
32位 Windows 版本,没毛病
32位下好后右键属性一看版本型号、安装包信息都TM是64位的
不错,还非常贴心的附上了下载链接。
然而评估版本是不能激活的,这坑爹文章