微软发布轻量级实时文本转语音模型——VibeVoice-Realtime-0.5B。该模型不仅支持流式文本输入,还能稳定生成长语音,它的应用场景也充满了想象空间:
- 你可以用它来构建实时 TTS 服务,用于播报动态数据流;
- 更关键的是,它能让大语言模型(LLM)在生成第一个 Token 时就立即「开口说话」,远早于完整回答。
根据硬件配置的不同,模型产生首个可听见音频的延迟大约为 300 毫秒。
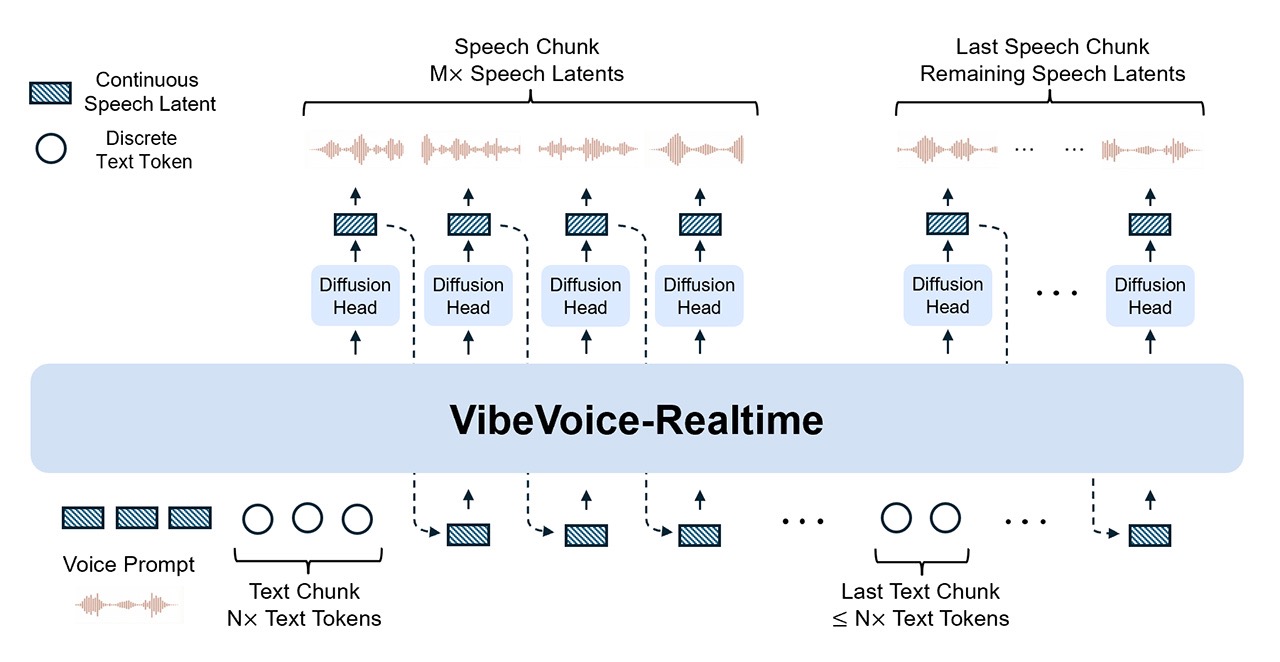
在技术实现上,VibeVoice-Realtime 采用了一种巧妙的交错式窗口化设计:
- 模型会增量地对输入文本块进行编码,同时并行利用先前的上下文信息,持续推进基于扩散模型的声学潜变量生成。
- 与支持多说话人和长篇语音的完整版本不同,流式模型移除了语义 Tokenizer,完全依赖一个高效的声学 Tokenizer——其运行帧率极低,仅为 7.5 Hz。
VibeVoice-Realtime-0.5B 简介
模型核心特性
- 参数规模:0.5B(5 亿),对部署极为友好。
- 实时 TTS:首个可听见的音频延迟约 300 毫秒。
- 流式文本输入:支持边输入边合成。
- 鲁棒的长语音生成:可稳定输出高质量的长段语音。
时版本只支持单一说话人。如果需要多人对话式语音生成,可以使用 VibeVoice 系列的其他模型。此外,该模型主要面向英语,在其他语言上可能会产生不可预知的结果。



最新评论
chmod +x之前一定要先把目录cd到安装文件所在的文件夹直接chmod有时不起作用
开dlna后,文件导入真的看不到怎弄
并不完全相同
是不是和KB5077241更新日志重复了