
Gemini 3 系列中速度最快、性价比最高的模型——Gemini 3.1 Flash-Lite 正式发布!该模型专为大规模、高频负载场景量身打造,在同级别模型中有着极高的「质价比」。
从现在开始,你就可以在 Google AI Studio 和 Vertex AI 平台,抢先体验 3.1 Flash-Lite 预览版。
兼顾性能与极致性价比
Gemini 3.1 Flash-Lite 的定价极具竞争力:
- 每百万输入 Token 0.25 美元
- 每百万输出 Token 1.50 美元
根据 Artificial Analysis 的基准测试,在保持甚至超越原有输出质量的前提下,它的首个 Token 响应时间(TTFT)比 2.5 Flash 快了 2.5 倍,输出速度提升了 45%。这一表现为高频业务流带来了极致的低延迟,能帮开发者轻松构建出丝滑、实时的交互体验。
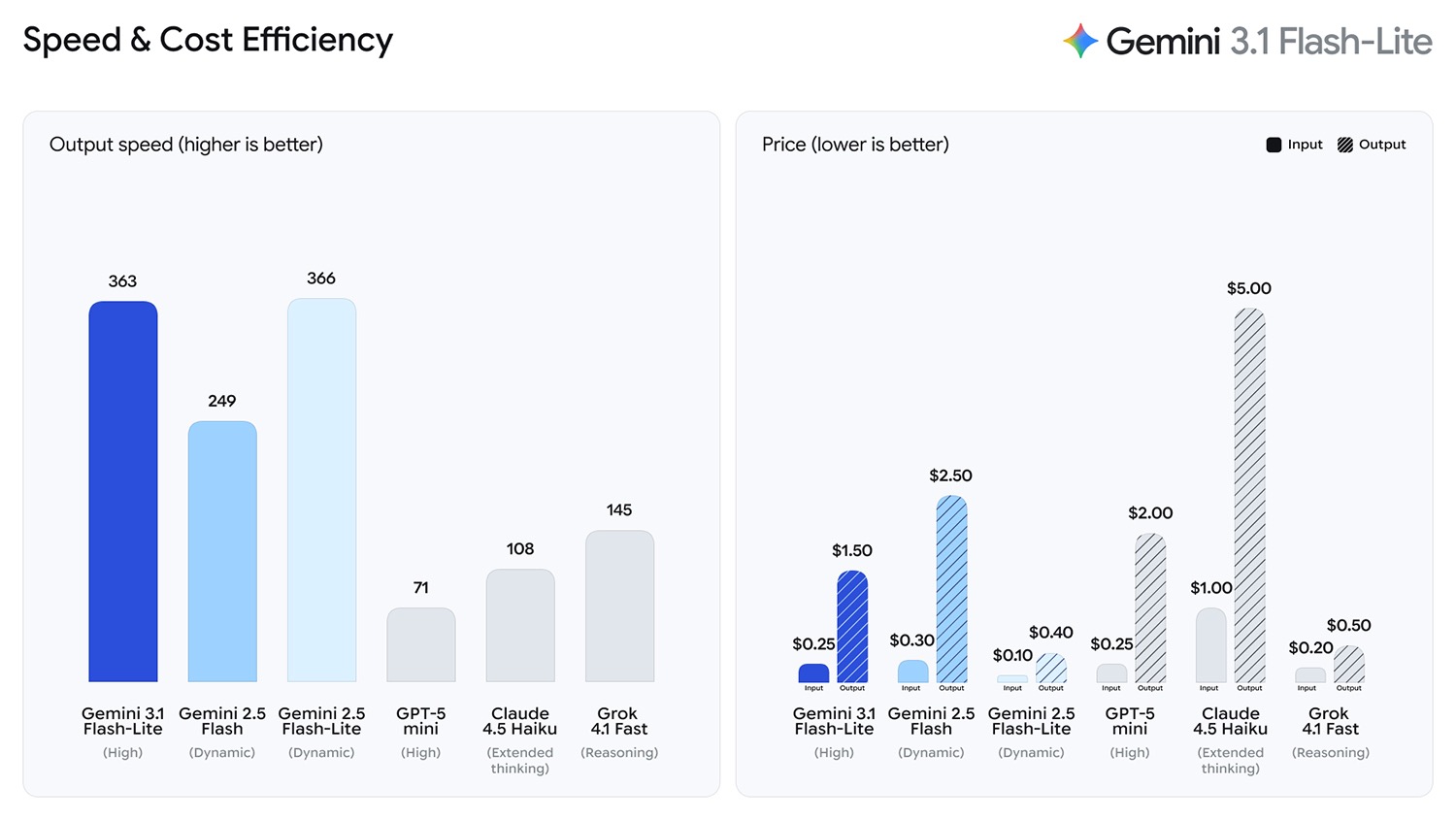
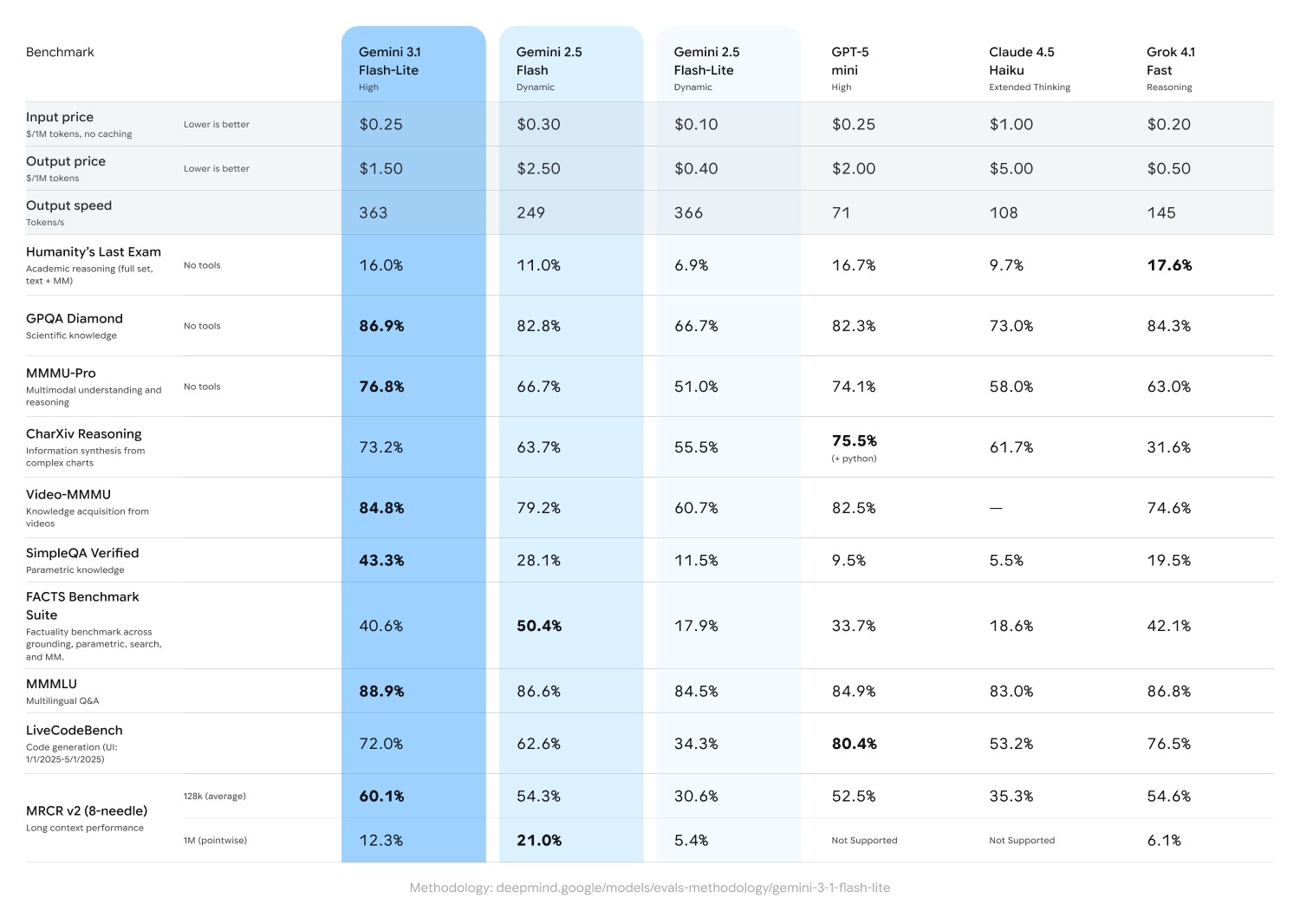
在权威的 Arena.ai 排行榜上,3.1 Flash-Lite 拿下了 1432 的 Elo 积分。放眼同级别模型,它在逻辑推理和多模态理解方面的综合表现都遥遥领先——不仅在 GPQA Diamond 测试中取得 86.9% 的高分,在 MMMU Pro 中也达到了 76.8%。其综合表现甚至反超了 2.5 Flash 等上一代更大尺寸的 Gemini 模型。
赋予开发者「弹性思考」控制权
除了硬核的性能指标,Gemini 3.1 Flash-Lite 在 AI Studio 和 Vertex AI 平台中,都标配了「思考深度」调节功能。这项设计能将控制权完全交还给用户,让你能灵活决定模型在特定任务上,要投入多少算力去「思考」——这对高效管理高频工作负载至关重要。
得益于此,3.1 Flash-Lite 既能胜任海量文本翻译、内容安全审核等成本敏感型任务,也能在自动生成 UI 界面与交互大屏、推演虚拟仿真或执行复杂操作指令等需要深度推理的重负载场景中挑起大梁。








最新评论
chmod +x之前一定要先把目录cd到安装文件所在的文件夹直接chmod有时不起作用
开dlna后,文件导入真的看不到怎弄
并不完全相同
是不是和KB5077241更新日志重复了