
本文旨在深入解析 Windows 平台上的 AI 创新,重点介绍 Microsoft 应用科学团队是如何通过多学科融合的方法,在算力功耗、推理速度和内存效率方面实现业界领先的 SLM(小语言模型)—— Phi Silica 的重大突破。
Phi Silica 已集成至 Windows 11 Copilot+ PC,为新一代 Copilot+ PC 体验提供核心支持。具体功能包括「Click to Do」(预览版)、Word 和 Outlook 的本地智能重写及摘要能力,并为开发者提供即插即用、预优化的 SLM 解决方案。
背景
2024 年 5 月,微软正式发布了 Copilot+ PC 标准。这一代设备内置 NPU(神经处理单元),算力可达每秒 40 TOPS(万亿次运算)。在发布会上,微软首次展示了 Phi Silica——一款专为 Snapdragon X 系列 NPU 打造的本地 SLM。
Phi Silica 是 Phi 系列模型的姊妹产品,充分发挥了 Copilot+ PC 内置 NPU 的并行加速优势。在 2024 年 11 月的 Ignite 大会上,微软进一步宣布:开发者可自 2025 年 1 月起,通过 API 直接调用 Phi Silica,将语言智能能力无缝集成到应用中。开发者无需关注模型优化细节或额外定制,因为 Phi Silica 已经实现了完善的预调优,可以「开箱即用」。
Copilot+ PC 拥有全天候的续航能力,NPU 可以长时间、持续执行 AI 任务,后台处理不间断,同时对系统资源的影响极小。得益于与云端的深度连接与协同,Copilot+ PC 的智能性能实现了质的飞跃:
- 在本地运行 AI 工作负载时,综合算力可达传统方案的 20 倍,能效高达 100 倍。
- 在 TOPS、功耗和成本等维度上,NPU 都要优于 GPU。同等条件下,NPU 可以稳定运行参数量在 3B 到 7B 级别的 SLM,具备涌现性智能,并以半实时方式服务于操作系统后台,为用户提供无限低延迟的智能问答,且无需额外订阅费用。
这不仅是计算范式的变革,更让强大推理型智能体首次成为操作系统服务的一部分,释放了应用与服务创新的巨大潜力。
原始浮点模型
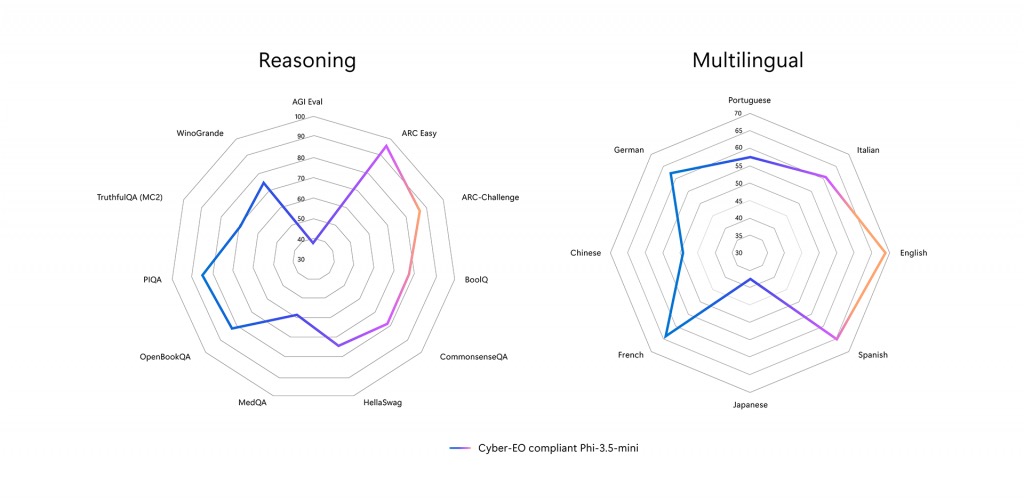
Phi Silica 基于 Phi-3.5-mini(符合 Cyber-EO 规范的定制版本)开发,并针对 Windows 11 场景进行了深度优化。该模型支持 4k 级别的上下文长度,覆盖多种主流语言(包括但不限于英语、简体中文、法语、德语、意大利语、日语、葡萄牙语、西班牙语等),并针对产品级体验进行了若干关键增强。
一个语言模型(如 Phi)通常包含以下核心组件:
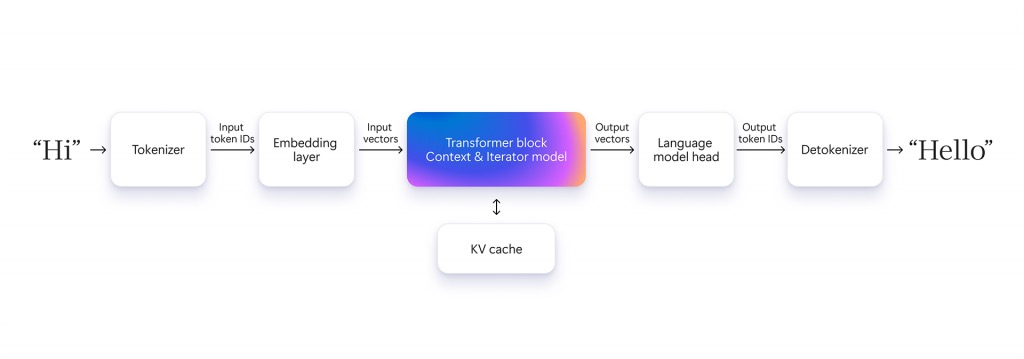
- 分词器(tokenizer):将输入文本切分为更小的单元,然后按预设词表将其映射为索引。分词操作是人类语言与模型内部表示的桥梁。
- 反分词器(detokenizer):执行上述过程的逆运算,将模型生成结果还原为自然语言文本。
- 嵌入模型(embedding model):将每个 Token 的离散 ID 映射到连续的高维向量,捕捉语义信息。这些归一化向量的方向承载了上下文与含义。
- Transformer 块:对输入嵌入向量执行变换,输出新的向量(或称为隐藏状态),用于预测下一个最可能跟随的 Token。
- 语言模型头(language model head):根据 Transformer 的输出,计算最有可能生成的下一个 Token。
基于 Prompt(提示词)生成响应,Transformer 通常包括两个主要阶段:
- 上下文处理:模型首先处理输入 Token,计算键值(KV)缓存,并生成隐藏状态与首个输出 Token。此阶段以矩阵乘法等高并行计算为主,对算力和能效要求极高。
- 逐 Token 生成:随后,模型以自回归方式逐步生成每个新的 Token,每生成一个 Token,就将其作为上下文的一部分,用于预测下一个,直到生成终止标记或满足用户设定的条件。
即便是参数规模较小的 SLM(如 Phi),上述流程的计算与资源压力依然不容小觑:
- 上下文处理阶段:对设备算力消耗极大,尤其在用 GPU 加速时,能效虽然高,但功耗也很可观。
- Token 生成阶段:则对内存性能有极高要求,每一步都需高效访问与存储 KV 缓存。虽然计算压力相对较小,但内存带宽和延迟直接影响生成速度。因此,如何在有限内存下高效生成,始终是一个技术难题。
Copilot+ PC 内置的 NPU 专为高能效 AI 计算定制,支持在单瓦级功耗下,实现高达数十 TOPS 的性能。以 Snapdragon X Elite 平台为例:
- Phi Silica 的上下文处理仅需 4.8 mWh(毫瓦时)能耗,Token 生成在 NPU 上运行时,要比 CPU 方案降低了 56% 的能耗。
- 凭借 NPU 的加持,Phi Silica 能在本地流畅运行,几乎不占用 CPU 和 GPU 的计算资源,内存和能耗也极具优势。
这让如此高能力、强泛化的 SLM 能够轻松融入用户的各类场景,极大提升设备主任务体验的流畅性和稳定性。
作为专用领域处理器,NPU 需要一系列独特的优化方法,来充分释放性能与效率。微软结合多项技术,既保证了准确率,又实现了最佳的效率和性能平衡。这些关键经验也可为其他 SLM 的本地化部署提供了参考。
接下来的技术细节将以如何将 Transformer 块高效优化并下放至 NPU 为核心展开。至于分词、嵌入和模型输出部分,这些主要是查表操作,对计算资源需求不高,因此仍由 CPU 负责。
创建 Phi Silica
面对原始浮点模型的庞大体量、目标硬件的内存限制,以及对速度、内存占用和能效等多维性能指标的高要求,微软在设计 Phi Silica 时,明确确立了以下几大核心特性:
- 采用 4-bit 权重量化,最大程度提升推理速度、降低内存占用。
- 空闲状态下极低内存消耗,支持内存常驻,消除初始化开销。
- 在「短提示词」场景下,首 Token 响应极快,大幅增强交互体验。
- 支持 2k 及以上上下文长度,保证真实生产场景下的实用性。
- 全流程在 NPU 上运行,实现长时间、高能效本地智能。
- 在跨多语言场景下保持高准确率。
- 模型体积小巧,便于在 Windows 系统上大规模分发。
基于以上目标,微软针对当代 NPU 平台打造了 Phi Silica。在架构设计和工程优化上,贯穿了多层级创新,从训练后量化、推理软件的高效资源调度,到面向硬件底层的算子布局与模型图特定优化,进一步拓展了 SLM 本地部署的极限能力。具体成果体现在以下几个方面:
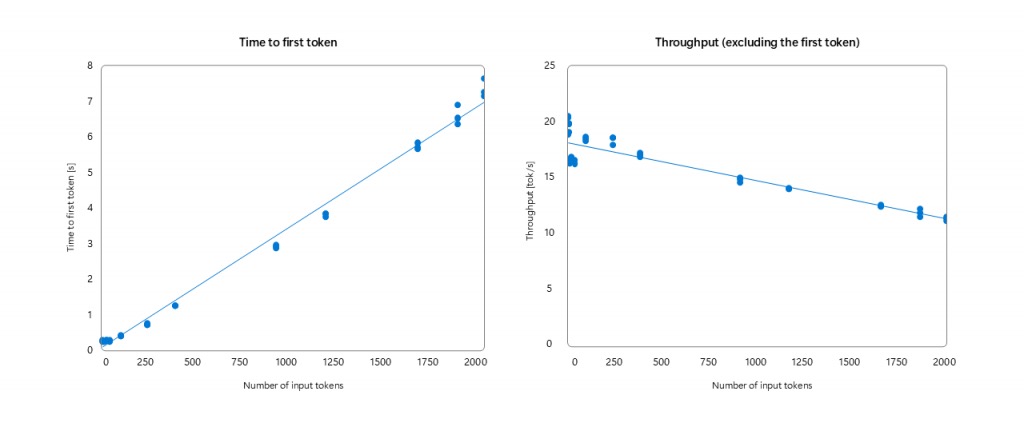
- 短提示词「首 Token 响应」可达 230 毫秒。
- 最大吞吐速率每秒 20 个 Token。
- 支持 2k 级上下文长度,即将扩展至 4k。
- 持续在 NPU 上高效运行上下文处理与 Token 生成。
训练后量化技术
为了真正实现低精度推理,从权重到激活全部量化,微软与学术界合作,共同推出了 QuaRot(Outlier-Free 4-Bit Inference in Rotated LLMs)。
QuaRot 作为「预量化修正器」,能够将整个大语言模型,包括全部权重、激活以及 KV 缓存,统一降至 4-bit 表示。其核心在于——通过「旋转」处理,将隐藏状态中的异常值(outlier)有效规避,却不影响模型输出,从而实现更高质量的低比特量化。QuaRot 的创新主要体现在以下两个方面:
- 非相关性处理:以往仅对权重量化的方法(如 QuIP、QuIP#),会通过矩阵旋转,对权重矩阵及 Hessian 进行前置与后置旋转。如果权重矩阵中某些元素的数量级远超平均值,容易形成「非相关性」突出,难以精确量化。非相关性处理就是通过旋转方法,让矩阵更「均匀」,从而提升量化友好性。不过,逐权重矩阵旋转、逆旋转会带来较高的计算开销。
- 计算等价性:QuaRot 进一步借鉴了 SliceGPT 提出的计算等价思想——在变换权重矩阵的情况下,不改变最终推理的输出。QuaRot 利用随机 Hadamard 变换对矩阵进行旋转,并采用等价算法将部分旋转步骤跨层融合、跳过,最终只需在 Transformer 块前后各执行一次整体旋转,极大降低了计算负担。此外,QuaRot 也支持对激活进行非相关性处理,从而让激活量化同样变得容易。
通过上述创新,模型结构整体被「旋转」到一个新的空间中,使权重、激活与 KV 缓存都能无损地用 4-bit 量化,并将精度损失降到最低。
4-bit 模型的实际收益
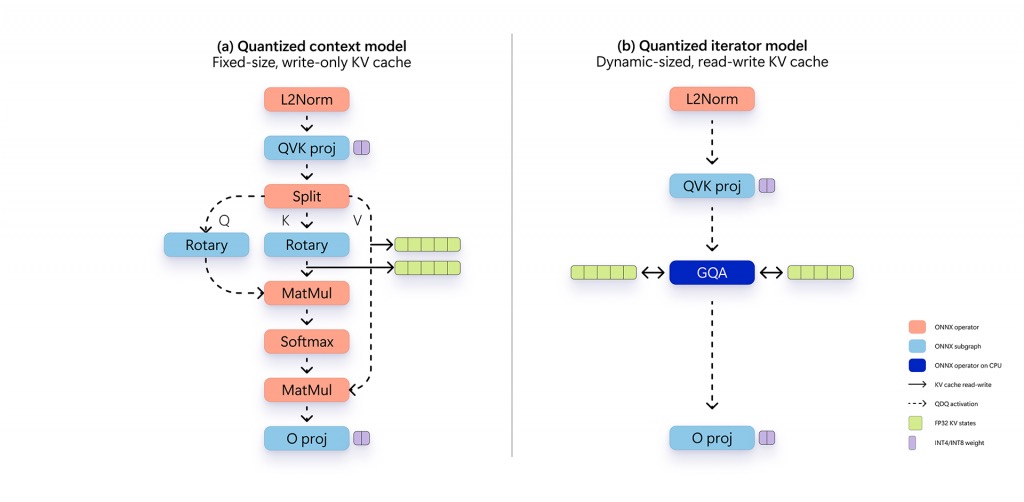
通过将模式权重量化为 4-bit,Phi Silica 达成了显著的内存占用优化。但要让 QuaRot 技术在 NPU 上高效支持 4-bit 量化推理,还需要根据 NPU 软件栈中量化支持的实际情况,进行多项定制与适配。最终,4-bit 版本的 Phi Silica 具备了以下关键结构:
- 旋转网络:基于原始浮点 ONNX 模型,将 Transformer 的 LayerNorm 替换为 RMS-Norm,并采用融合的 Hadamard 旋转,构建等价的旋转网络架构。
- 嵌入层:在嵌入层入口处一次性融合 QuaRot 旋转。
- 激活量化:激活(activation)采用非对称的逐张量四舍五入方式,从 ONNX 导出为 16-bit 无符号整数。
- 权重量化:权重采用 QuaRot + GPTQ 实现逐通道对称量化,量化到 4-bit,并写入旋转后的网络结构中。
- 线性层变换:为了在当前 NPU 软件栈上获得最优延迟表现,将所有线性层统一转换为 1×1 卷积(Conv2D),这更适合 Phi Silica 模型中特定矩阵规模的高效计算。
- 选择性混合精度:为了进一步提升精度,对重构误差较大的部分权重,采用逐张量的 8-bit 量化。该策略有助于 NPU 推理时,抑制静态量化对所有激活值的负面影响,但应严格控制使用比例以防模型膨胀。实际落地中,128 个权重矩阵中,仅 4-8 个采用 8-bit 量化。
- 语言模型头:在输出阶段,融合一次 QuaRot 的逆旋转,并采用 4-bit 分块量化,有效降低内存消耗。
相比常规的逐元四舍五入量化方式,QuaRot 能显著提升量化精度,尤其在逐通道低比特粒度量化场景下效果尤为突出。下表展示了 4-bit 量化前后在各类零样本学习任务(zero-shot,使用 lm-eval harness)中的基准表现:
| 零样本任务 | 浮点模型(%) | 4-bit QuaRot 权重 + 浮点激活(%) |
|---|---|---|
| piqa | 80.47 | 79.76 |
| winogrande | 72.77 | 72.38 |
| arc_challenge | 63.48 | 60.49 |
| arc_easy | 85.69 | 82.74 |
| hellaswag | 77.14 | 75.13 |
| mmlu_abstract_algebra | 45.00 | 38.00 |
| mmlu_business_ethics | 76.00 | 73.00 |
| mmlu_college_computer_science | 57.00 | 48.00 |
| mmlu_college_mathematics | 40.00 | 38.00 |
| mmlu_conceptual_physics | 71.91 | 67.23 |
| mmlu_formal_logic | 53.97 | 50.00 |
| mmlu_machine_learning | 57.14 | 52.67 |
持久驻留与内存效率优化
为了让 Phi Silica 持续常驻于内存、稳定应对长时间本地推理,模型的内存占用必须被严格控制在合理区间。微软通过定量分析和持续优化,针对内存管理的关键难题,采用了以下核心技术:
- 权重共享:上下文处理模块与 Token 生成模块(Token Iterator)共用同一组量化权重及大部分激活量化参数。这样不但将内存占用减少一半,还加快了模型初始化速度。实现方式是让 ONNX Runtime 内的两个模型计算图引用同一权重副本。
- 内存映射嵌入层:嵌入层的内存消耗与词表规模和嵌入维度成正比。采用内存映射文件方式存储嵌入矩阵,并将嵌入实现为查表操作,从而把动态内存占用降到近乎为零,无需将大型嵌入矩阵整体加载进内存。
- 关闭内存池分配器:ONNX Runtime 默认启用 Arena 分配器,会预分配大量内存以减少频繁分配与释放,这在部分场景下有帮助,但初始内存占用较高。由于 Phi Silica 的内存利用模式非常确定,关闭 Arena 分配器可直接带来整体内存效率的提升。
通过以上措施,加上 4-bit 量化模型的优化,Phi Silica 的总体内存需求减少了近 60%。
上下文长度扩展
在 NPU 面向的软件栈通常要求张量形状静态的背景下,如何突破 context processor 的序列长度上限,实现更长上下文处理,是让 SLM 具备真实落地应用价值的关键。为此,微软设计了两项互补创新,使得上下文长度能够灵活扩展,并支持流式 Prompt 处理:
- 滑动窗口方案:不再强制一次性处理整个提示词,而是将输入 Prompt 拆分成若干块,每块大小为 N(必要时,最后一块会补齐填充)。这样,分块后的上下文模型实际只需处理长度为 N 的序列,却能够维持总上下文长度不变。采用
N = 64,每一块按顺序处理,并同步更新 KV 缓存以保留历史信息。这种滑动窗口机制既加快了短 Prompt 的处理速度,也不损失长 Prompt 的吞吐能力,实现了处理时长与 Prompt 长度的线性关联。
- 动态共享 KV 缓存:如果 context processor 完全运行在 NPU 上,且其 KV 缓存为只读,效率虽高,但受限于各自序列长度,整体上下文容量会受限。为了突破这一限制,微软尝试在 NPU 与 CPU 之间灵活分摊上下文处理工作,兼顾处理速度与灵活性。最终,选择仅将 GroupQueryAttention 操作放在 CPU 执行,这使得 KV 缓存可读、可写,且支持动态扩展。不仅能跨上下文块共享历史,也能在 context processing 和 token iteration 间高效切换,大幅提升内存利用效率。通过 输入/输出绑定(IO Binding),在上下文处理时预分配充足内存,使 context processing 和 token iteration 能高效共享同一 KV 缓存资源。这种方案极大优化了内存效率和响应延迟,尤其在 KV 缓存规模随上下文长度呈二次增长的情况下,内存管理至关重要。
综合上述改进,Phi Silica 在短 Prompt 场景下具备更快速的首 Token 响应能力,同时保持高效的内存利用率,并最大程度继承了 NPU 驱动下的卓越能效表现。
安全对齐、负责任的 AI 及内容审核
Phi Silica 基于的浮点模型,已采用五阶段「break-fix」方法进行安全对齐,相关实践可参考技术报告:Phi-3 Safety Post-Training: Aligning Language Models with a “Break-Fix” Cycle。
Phi Silica 模型本身、系统架构及 API,均需经过负责任 AI 影响评估,及上线安全委员会的多轮审核。开发者 API 提供本地内容审核能力,确保平台合规和用户安全。具体流程详见:在 Windows App SDK 中上手 Phi Silica。
在快速演变、技术复杂的 NPU 时代,微软正在持续突破硬件与软件栈的极限。通过前沿量化理论创新,Phi Silica 在内存效率、能耗表现和推理延迟三大关键维度取得了卓越提升,而无需在体验和功能上进行妥协。
这一成果体现了微软对兼具强大能力与极致高效模型研发的坚定承诺。Phi Silica 作为 Copilot+ PC 的一部分,将强大高效的生成式 AI 深度融入 Windows 11,让每一位用户都能借助本地智能,释放个人和设备的全部潜能。


最新评论
现在可以了
32位 Windows 版本,没毛病
32位下好后右键属性一看版本型号、安装包信息都TM是64位的
不错,还非常贴心的附上了下载链接。