
大语言模型(LLM)的本质,是一种能够以「语境感知」的方式理解、生成和处理人类语言的高级 AI 系统。依托庞大的神经网络,并在海量数据集上的千锤百炼,这些模型不仅能总结摘要、解析句法,更能响应用户的「提示词」(Prompt),来生成连贯且逻辑自洽的文本。
这远不止是聊天机器人——它标志着计算范式正在从「指令式计算」转向「意图理解计算」。
01. AI 进化的里程碑:从 Transformer 到大模型时代
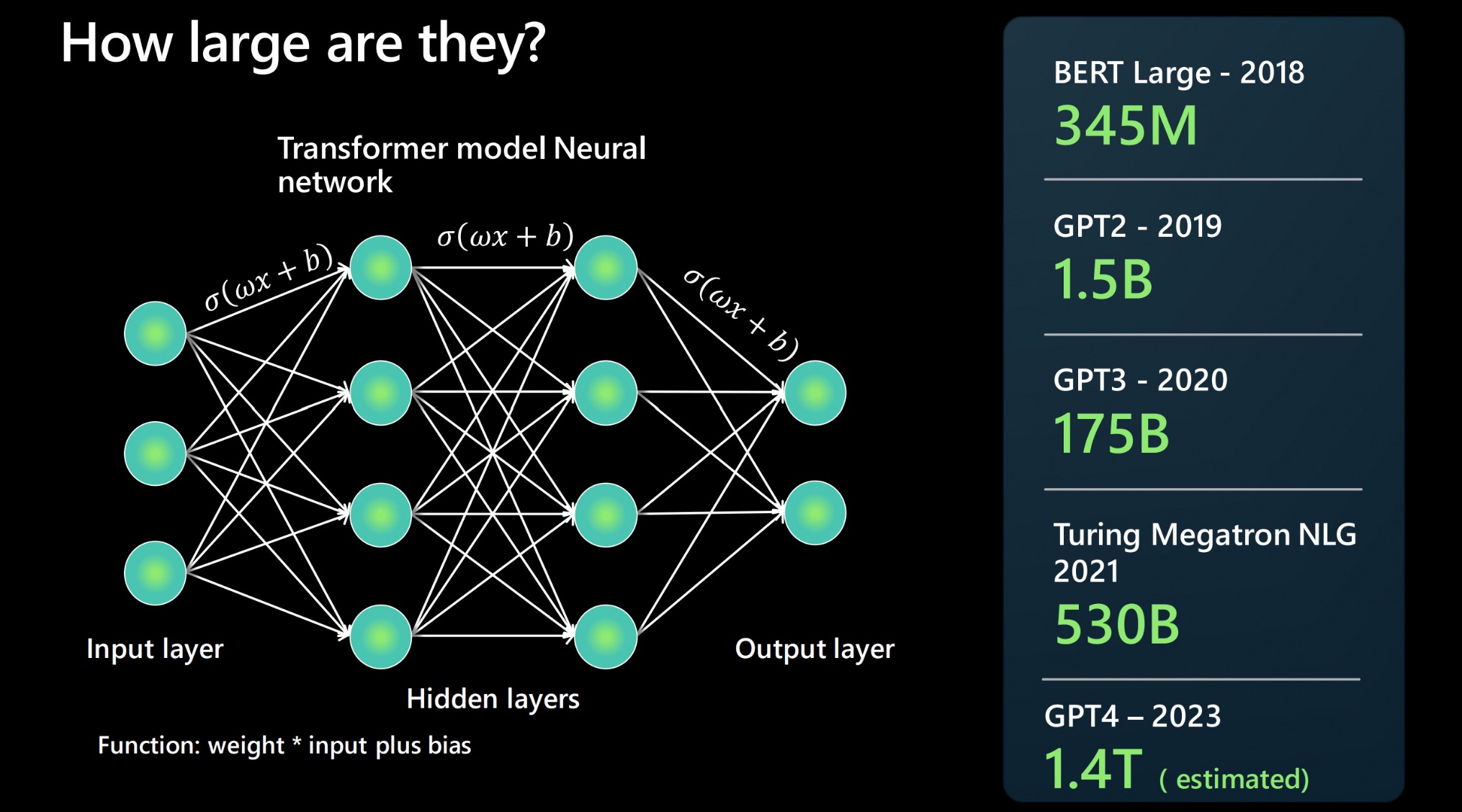
大语言模型(LLM)是机器学习、深度学习和自然语言处理(NLP)技术长期演进的最新结晶。这场变革的引爆点,可以追溯到 Google 在 2017 年发表的划时代论文——《Attention is All You Need》。
- 这篇论文提出的「Transformer 架构」,为后来 OpenAI 的 GPT 系列、Google 的 BERT,以及 Hugging Face 上无数开源模型奠定了基石。
- LLM 的出现不仅刷新了机器翻译、文本摘要和问答系统的性能基准,更逐渐成为现代 AI 应用开发的底层「操作系统」。它让我们得以用全新方式自动化任务,甚至重塑娱乐体验。
随着研究的深入,LLM 已经成为 AI 理论创新的基础平台,也迫使我们重新思考 AI 在社会中的角色:当机器开始「理解」语言,世界将如何改变?
02. 核心解密:大语言模型是如何运作的?
2.1 语言模型的基石:概率与预测
从根本上说,语言模型(包括 LLM)是在做一道极其复杂的「填空题」。它根据从海量文本中学到的规律,来预测序列中下一个「字或词」的出现概率。
这一过程被称为「自监督学习」(Self-supervised Learning)。通过将数以亿计的无标注文本喂给模型,让它不断尝试预测下一个 Token,并与真实文本比对。模型会持续缩小「预测结果」与「真实答案」之间的差距,通过反复迭代优化内部参数,最终掌握人类语言的句法、语义,乃至隐含的语境逻辑。
2.2 突破口:Transformer 架构
Transformer 彻底改变了游戏规则。与早期架构(如 RNN)不同,它支持「并行处理」,使得在大规模数据集上的高效训练成为可能,并能处理更长的文本序列——其核心武器正是「自注意力机制」(Self-Attention)。
2.3 理解「注意力」与神经网络
想象一下人类阅读时的习惯:我们会聚焦关键词,但忽略无关的虚词。Transformer 的自注意力机制正是对这一认知过程的模拟。它允许模型同时评估输入序列中所有 Token 之间的关联,无论它们在句子中相隔多远。
深度学习网络则构成了 LLM 的骨架。通过堆叠多层神经网络,LLM 能将原始数据逐步转化为对语言模式的深刻理解——从基础语法结构到复杂的语义推断。这种融合了 Transformer 与深度神经网络的架构,让机器的语言处理能力前所未有地接近人类水平。
03. 群雄逐鹿:主流模型大盘点
3.1 GPT 系列:生成式 AI 的领跑者
OpenAI 开发的 GPT(Generative Pre-trained Transformer)系列无疑是当前最耀眼的明星。从初代 GPT 起,该模型家族便致力于通过预训练学习语言模式,来生成符合语境的回答。
从 GPT-2 到 GPT-5,OpenAI 不断验证着「大力出奇迹」的「缩放定律」。以 GPT-3 为例,其拥有 1750 亿参数,这种量级的跃升让他不仅能撰写文章,还能编写可运行的代码。GPT 系列不仅是技术的突破,更引发了全球关于「通用人工智能」(AGI)与 AI 创作伦理的广泛讨论。
3.2 BERT:理解语言的大师
如果说 GPT 擅长「写」,那么 Google 的 BERT(Bidirectional Encoder Representations from Transformers)则更擅长「读」。
BERT 引入了「双向注意力机制」,能同时利用上下文信息来理解单词的含义。这种「上帝视角」让他在理解搜索意图、提升翻译质量等任务上表现卓越。如今,BERT 已成为众多 NLP 任务的标准基座,并衍生出大量适配不同语言和场景的变体。
3.3 T5:万物皆可 Text-to-Text
Google Research 推出的 T5(Text-to-Text Transfer Transformer)提出了一个优雅的统一框架:将所有 NLP 任务都视为「文本到文本」的转换问题。无论是翻译、摘要还是分类,输入是文本,输出也是文本。这种标准化的输入输出格式,极大简化了模型的训练与部署流程。
04. 开发者指南:构建与落地
4.1 基础设施:自研还是调用?
从零开始训练一个大语言模型,需要堪比顶级 AI 实验室的算力(如 GPU 集群)和海量数据储备。因此,对绝大多数开发者来说,主流使用路径有两条:
- API 调用:直接调用 OpenAI、Anthropic、DeepSeek 和阿里百炼等模型的接口。
- 微调 (Fine-tuning):基于 LLaMA、Mistral、Qwen 等开源模型,利用私有数据进行定制化训练。
4.2 技术栈与工具
- 云平台:AWS、Google Cloud 和 Azure 提供了必要的 GPU 算力支持。
- 框架:PyTorch 和 TensorFlow 是训练和微调的标配;Hugging Face 和魔搭社区等,则是模型仓库的首选。
- 部署:Docker 和 Kubernetes 负责容器化与编排,确保模型在生产环境的高可用性。
- 前端集成:TensorFlow.js 可以在浏览器端运行轻量级模型,Python 的 Flask/FastAPI 则常用于搭建后端 API。
4.3 微调的艺术
通用的预训练模型往往是「博而不精」。通过在特定领域的精选数据集上进行微调,可以让模型从「通才」蜕变为「专家」。此外,「迁移学习技术」也能在数据有限的情况下,有效提升模型在垂直场景中的表现。
05. 现实挑战:阴影下的思考
尽管 LLM 光芒万丈,但在落地过程中仍然面临着严峻挑战:
- 偏见与伦理:模型的数据源通常来自互联网,难免会沾染人类社会的偏见。若不加以干预,「招聘 AI」可能会歧视特定群体,聊天机器人也可能输出有害信息。这就要求引入「偏见审计」和严格的伦理对齐机制。
- 算力与环境成本:训练 GPT-5、DeepSeek 这类巨无霸模型需要处理 TB 级数据,消耗惊人的电力。如何在性能与碳中和之间取得平衡,已经成为行业必须直面的课题。
- 隐私与安全:大语言模型可能会在无意中泄露训练数据中的敏感信息。企业在应用时,必须严格遵守 GDPR 等法规,并采用差分隐私等技术手段保护数据安全。
06. 行业应用:被重塑的生产力
LLM 正在从实验室加速走向产业深处:
- 医疗健康:辅助医生分析病历和医学文献,甚至基于基因图谱提供个性化诊疗建议。
- 金融服务:除了智能客服,LLM 还被用于反欺诈系统,通过分析交易模式识别异常行为。
- 软件开发:GitHub Copilot、Claude Code、Google Antigravity 等工具让 AI 结对编程成为现实,可以自动生成代码和测试用例,大幅提升开发效率。
- 教育:通过分析学生的学习风格,生成个性化的教材和习题,真正实现因材施教。
07. 未来图景:通向 AGI 之路
大语言模型(LLM)的未来将走向何方?
- 多模态融合:不再局限于文本,未来的模型将能自如处理图像、音频和视频,成为真正的全能助手。
- 逻辑与因果:研究人员正致力于提升模型的逻辑推理能力,让他不仅能「说得通」,更能「想得对」。
- 迈向 AGI:随着模型展现出越来越强的泛化能力,许多人相信,LLM 是通往通用人工智能(AGI)的必经之路——最终目标是创造出能像人类一样在任何领域学习和应用的智能体。
总的来说,大语言模型不仅是技术的飞跃,更是人类探索智能边界的先锋。对于开发者和技术从业者而言,保持好奇、持续学习、动手实践,才是立足于这个 AI 新时代的唯一法门。
最新评论
https://www.sysgeek.cn/windows-11-preview-pane-not-working-and-fix/
过一段时间后又自动开启实时防护了,方法不行
通过组策略禁用 Windows Defende有效,windows11家庭版,需要先关闭篡改防护且关闭实时防护,再在编辑表中做对应操作,随后重启
终于找到了,很实用,感谢作者