在 Meta Connect 2024 活动上,Mark Zuckerberg 宣布了全新的 Llama 3.2 模型系列,在开源模型中首次引入了对多模态图像的支持。
Llama 3.2:针对设备本地任务优化
Llama 3.2 系列包含了两个较小的模型——Llama 3.2 1B 和 3B,它们经过深度优化,专为本地和边缘设备任务而设计,能够在移动设备和笔记本电脑上高效运行。
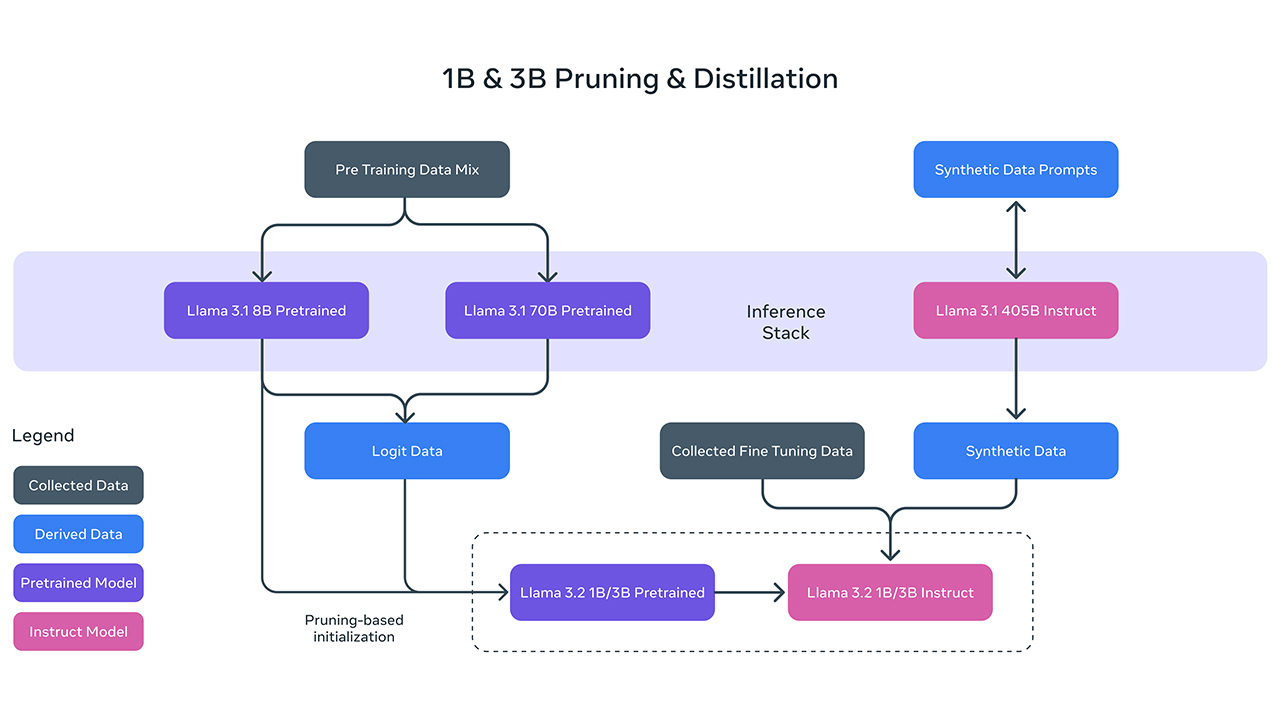
Llama 3.2 1B 和 3B 是通过对 Llama 3.1 8B 和 70B 模型进行剪枝和蒸馏得到的,非常适合用于本地任务的:摘要、指令跟随、文本重写,甚至能本地调用函数生成动作意图。
Meta 表示,Llama 3.2 的性能超越了 Google 的 Gemma 2 的 2.6B 和微软的 Phi-3.5-mini 模型。开发者还可以将它们部署在高通和 MediaTek 等 ARM 平台上,以支持多种 AI 应用。
Llama 3.2:为 AI 赋予视觉能力
规模更大的 Llama 3.2 11B 和 90B 模型引入了多模态图像支持,并取代了只支持文本的 Llama 3.1 8B 和 70B 模型。Meta 表示,它们可以与 Anthropic 的 Claude 3 Haiku 和 OpenAI 的 GPT-4o mini 等封闭模型相媲美。
Llama 3.2 模型将与 Meta AI 聊天机器人集成,用户可以在网络、WhatsApp、Instagram、Facebook 和 Messenger 上进行体验。作为视觉模型,你可以上传图像并提出相关问题。例如,上传一张食谱图片,模型可以分析并提供详细的制作步骤;你还可以让 Meta AI 捕捉你的面部图像,并在不同的场景或肖像中重新构想你的形象。
这些视觉模型在解读图表等信息时表现非常出色,尤其是在 Instagram 和 WhatsApp 社交平台上,它们还能为用户自动生成字幕。





最新评论
关闭「安全启动」或改用 grub 之后。通过 grub 启动 Windows 而不使用 UEFI 的 Windows Boot Manager,「设备加密」会认为启动路径不可信,就会彻底隐藏。
应用安装失败,错误消息: 从 (Microsoft.NET.Native.Framework.2.2_2.2.29512.0_x64__8wekyb3d8bbwe.Appx) 使用程序包 Microsoft.NET.Native.Framework.2.2_2.2.29512.0_x64__8wekyb3d8bbwe 中的目标卷 C: 执行的部署 Add 操作失败,错误为 0x80040154。有关诊断应用部署问题的帮助,请参阅 http://go.microsoft.com/fwlink/?LinkId=235160。 (0x80040154)
之前装双系统时关了BitLocker,后来找不大设备加密了(原本有的)是怎么回事
补充一下哈,如果大家想看得更为完整。可以输入: slmgr.vbs -xpr 查询Windows是否永久激活 slmgr.vbs -dli 查询到操作系统版本、通过激活的渠道、后五位产品密钥、许可证状态等信息 slmgr.vbs -dlv 查询所有Windows的激活信息,包括:激活ID、安装ID、激活截止日期等信息