
Ollama 的出现为 AI 爱好者带来了新的可能性。越来越多的工具和平台,如 OpenAI Translator、NextChat 和 LoboChat 等,都已经支持调用 Ollama 在本地运行的大语言模型 (LLM)。这不仅为 AI 新手提供了一种便捷的「入门玩法」,也为经验丰富的开发者开辟了新的探索途径。
Ollama on Windows(预览版)的推出,彻底改变了在 Windows 设备上进行 AI 开发的格局。无论你是 AI 领域的探索者,还是刚刚踏入该领域的「试水玩家」,Ollama 都为你指明了一条清晰而富有潜力的道路。
什么是 Ollama?
Ollama 是一个开创性的人工智能 (AI) 和机器学习 (ML) 工具平台,它彻底简化了 AI 模型的开发和使用流程。
在 AI 技术社区中,模型的硬件需求和环境配置一直是令人头疼的问题。Ollama 应运而生,正是为了解决这些关键痛点:
- 它提供了一套直观高效的工具,无论你是 AI 专家还是初涉此道的新手,都能轻松上手。
- Ollama 让先进的 AI 模型和计算资源变得触手可及,不再是少数人的「专利」。
- 对 AI 和 ML 社区来说,Ollama 的出现具有里程碑意义,它加速了 AI 技术的普及,让更多人能够实践自己的 AI 创意。
Ollama 的独特优势
Ollama 能够从众多 AI 工具中脱颖而出,主要得益于以下几个关键特性:
- 智能硬件加速:Ollama 能自动识别并充分利用 Windows 系统中的最优硬件资源。无论是 NVIDIA GPU、AMD GPU,还是支持 AVX、AVX2 指令集的 CPU,Ollama 都能实现针对性优化,大幅提升 AI 模型的运行效率。这意味着,你可以把更多精力放在项目本身,而不是纠结于复杂的硬件配置。
- 零虚拟化要求:告别繁琐的虚拟机搭建和复杂的环境配置。Ollama 让你能够直接开始 AI 项目开发,整个流程变得简单快捷。这种便捷性极大地降低了 AI 技术的入门门槛。
- 丰富的开源模型库:Ollama 托管了一个全面的开源 AI 模型库,包括先进的图像识别模型 LLaVA、Google 最新的 Gemma 3 模型 和微软的 Phi-4 模型家族等。这个「AI 武器库」让你可以轻松尝试各种开源模型,无论是文字交流、图像处理还是其他 AI 任务,总能找到合适的工具。
- 便捷的常驻 API:Ollama 的常驻 API 会在后台默默运行,随时准备将 AI 功能无缝整合到你的项目中。这意味着,强大的 AI 能力可以自然而然地融入你的开发流程,无需复杂的额外设置。
通过这些精心设计的功能,Ollama 不仅解决了 AI 开发中的常见痛点,还大大降低了 AI 技术的应用门槛,为 AI 的广泛应用铺平了道路。
第 1 步:在 Windows 上安装 Ollama
欢迎来到 AI 和机器学习的新纪元!接下来,让我们一步步引导你完成 Ollama 的安装过程。
Ollama on Windows 需要 Windows 10 或更高版本。
1打开浏览器,访问 Ollama on Windows 页面,点击下载按钮,获取OllamaSetup.exe安装程序。
2双击安装文件,点击「Install」开始安装。
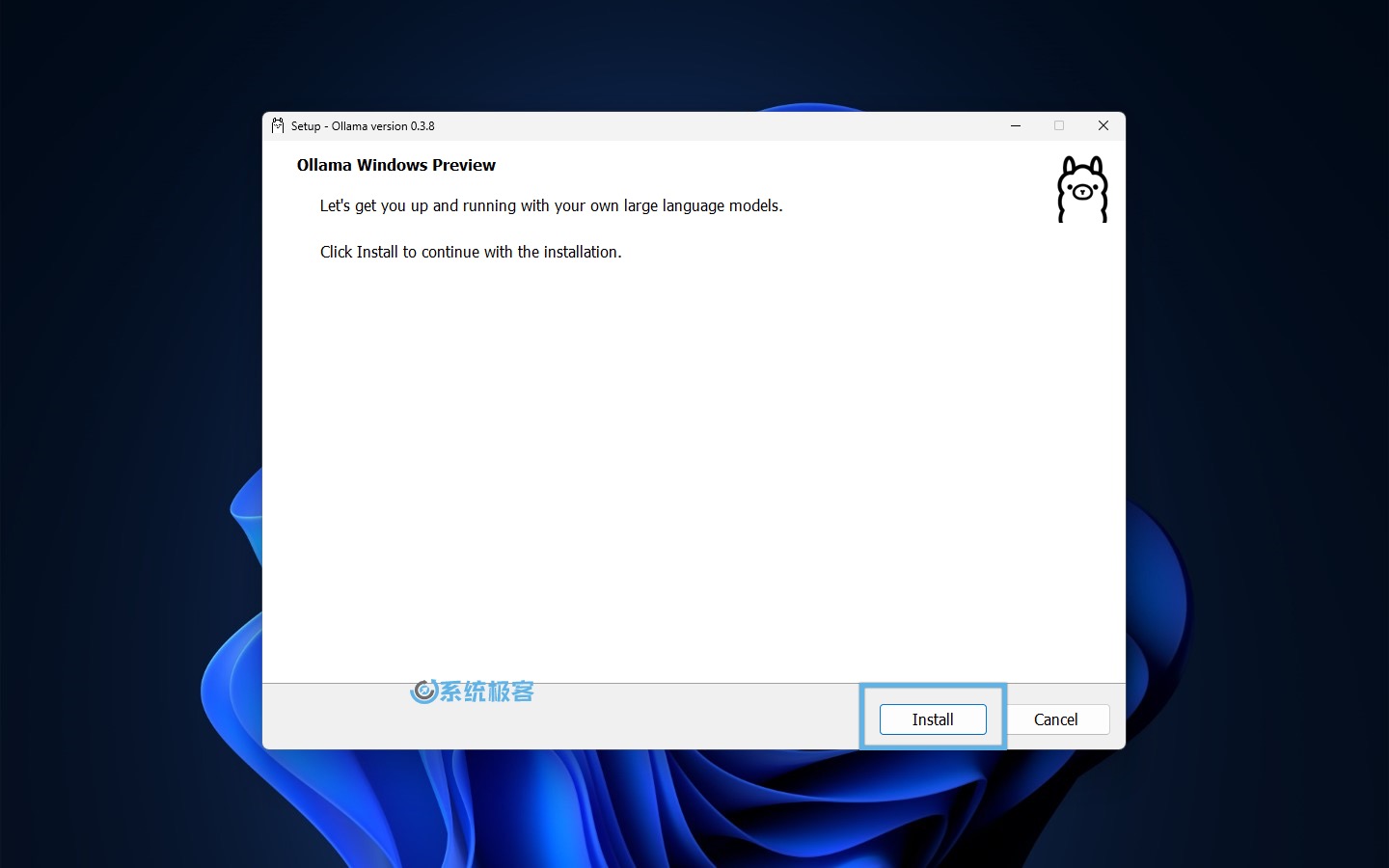
3安装完成后,右键点击系统托盘中的 Ollama 图标,选择「Quit Ollama」退出后台运行。
4(可选)Ollama 默认会随 Windows 自动启动,你可以在「文件资源管理器」的地址栏中访问以下路径,删除其中的Ollama.lnk快捷方式文件,阻止它自动启动。
%APPDATA%\Microsoft\Windows\Start Menu\Programs\Startup
第 2 步:配置 Ollama on Windows
为了充分发挥 Ollama 的潜力,我们需要对「环境变量」进行一些自定义配置:
1使用Windows + R快捷键打开「运行」对话框,输入以下命令,然后按Ctrl + Shift + Enter以管理员权限打开「环境变量」配置窗口。
C:\Windows\system32\rundll32.exe sysdm.cpl, EditEnvironmentVariables
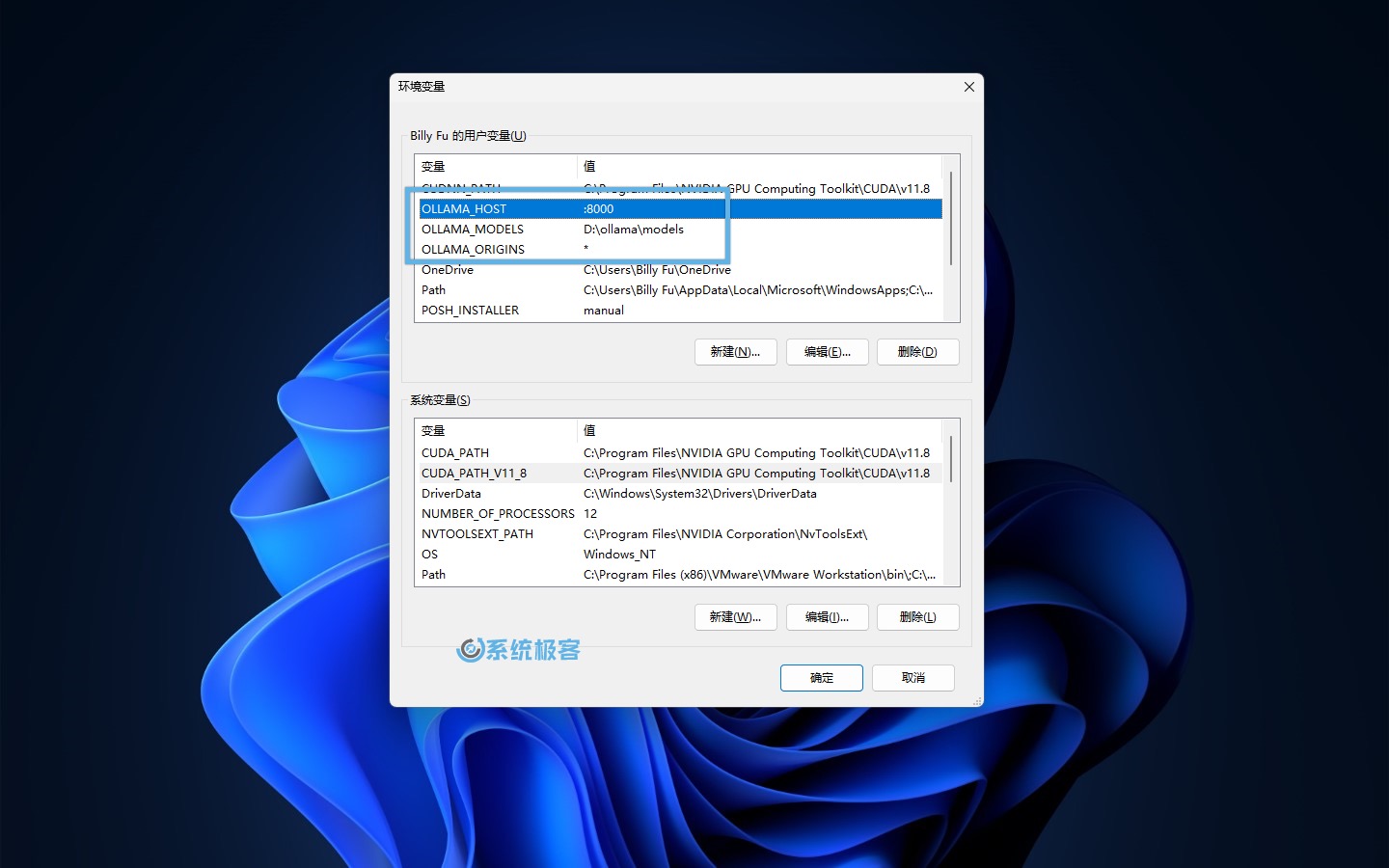
2在「用户变量」中,根据需要添加以下环境变量。
2.1 更改模型存放路径
Ollama 的默认模型存储路径如下:
C:\Users\%username%\.ollama\\models
无论你的 C 盘空间大小,需要安装多少模型,都建议换一个存放路径,例如:
- 变量名:
OLLAMA_MODELS - 变量值:
D:\ollama\models(示例路径,请根据实际情况调整)
2.2 更改 Ollama API 访问地址和侦听端口
Ollama API 的默认访问地址和侦听端口是http://localhost:11434,只能在装有 Ollama 的系统中直接调用。如果要在网络中提供服务,请修改 API 的侦听地址和端口:
- 变量名:
OLLAMA_HOST - 变量值(端口):
:8000
只填写端口号可以同时侦听(所有) IPv4 和 IPv6 的:8000 端口。
要使用 IPv6,需要 Ollama 0.0.20 或更高版本。另外,可能需要在 Windows 防火墙中开放相应端口的远程访问。
2.3 允许浏览器跨域请求
Ollama 默认只允许来自127.0.0.1和0.0.0.0的跨域请求,如果你计划在 LoboChat 等前端面板中调用 Ollama API,建议放开跨域限制:
- 变量名:
OLLAMA_ORIGINS - 变量值:
*
2.4 重启 Ollama 并测试 API 访问
1在「开始」菜单中找到并重新启动 Ollama。
2右键点击系统托盘中的 Ollama 图标,选择「View log」打开命令行窗口。
3分别执行以下命令,查看新配置的环境变量是否生效:
echo %OLLAMA_MODELS%
echo %OLLAMA_HOST%
echo %OLLAMA_ORIGINS%
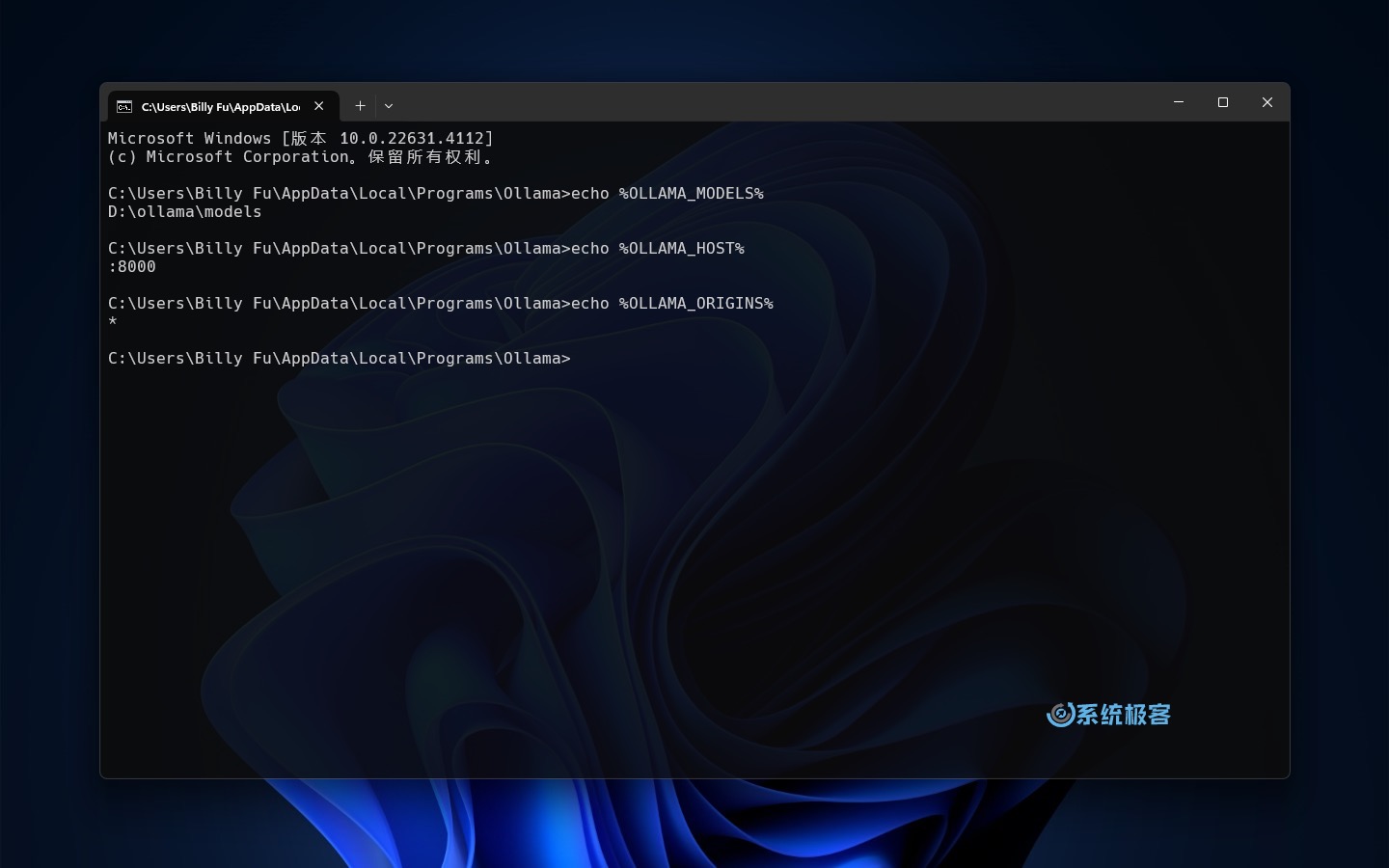
4找一台同一局域网内的电脑,在浏览器中访问 Ollama API 地址和端口,验证访问是否正常。
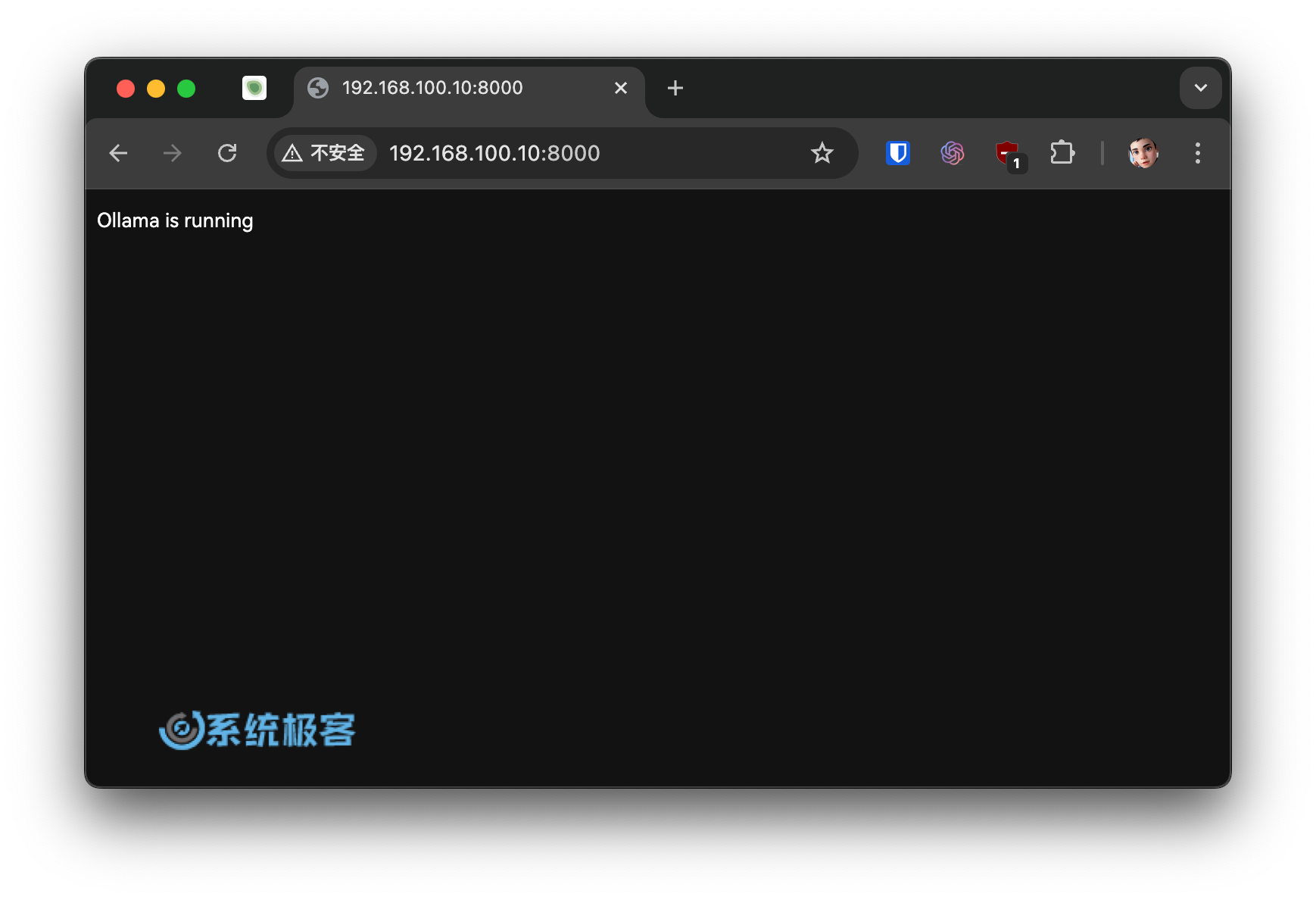
第 3 步:使用 Ollama on Windows
3.1 获取并运行 AI 模型
现在,我们开始从 Ollama 模型库中拉取开源 AI 模型,操作步骤如下:
1右键点击系统托盘中的 Ollama 图标,选择「View log」打开命令行窗口。
2执行以下命令来加载并运行模型:
ollama run <模型名称>
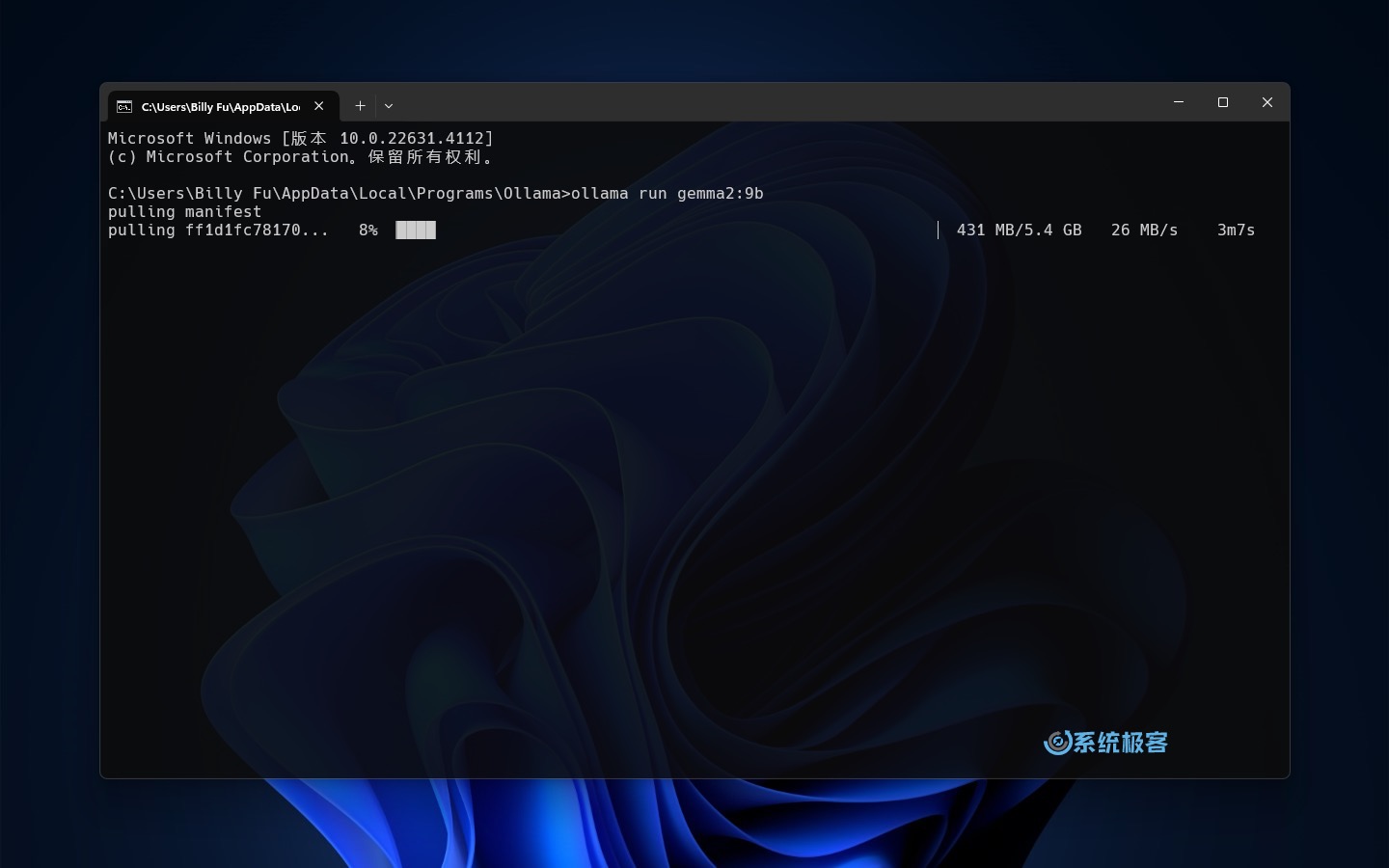
执行命令后,Ollama 会自动从模型库中下载并加载你所选的模型,所需时间取决于你的网速和模型大小。
在 Ollama 模型库中,比较常用的 AI 模型有:
| 模型 | 默认参数 | 大小 | 安装命令 | 发布组织 |
|---|---|---|---|---|
| Llama 3.3 | 70B | 43GB | ollama run llama3.3 | Meta |
| Mistral | 7B | 4.1GB | ollama run mistral | Mistral AI |
| mixtral | 8x7b | 26GB | ollama run mixtral | Mistral AI |
| Phi-4 | 14B | 9.1GB | ollama run phi4 | Microsoft Research |
| phi4-reasoning | 14B | 11GB | ollama run phi4-reasoning | Microsoft Research |
| LLaVA | 7B | 4.7GB | ollama run llava | Microsoft Research |
| Gemma3 | 4B | 3.3GB | ollama run gemma3 | |
| Qwen3 | 8B | 5.2GB | ollama run qwen3 | 阿里巴巴 |
| Command R | 35B | 19GB | ollama run command-r | Cohere |
| deepseek-v3 | 617B | 404GB | ollama run deepseek-v3 | 深度求索 |
| deepseek-r1 | 7B | 4.7GB | ollama run deepseek-r1 | 深度求索 |
运行 7B 至少需要 8GB 显存,运行 13B 至少需要 16GB 显存。
3.2 在命令行中使用模型
模型加载完毕后,我们就可以开始与 AI 进行对话了。Ollama 支持各种开源模型来完成不同类型的任务。让我们来看看如何使用这些模型:
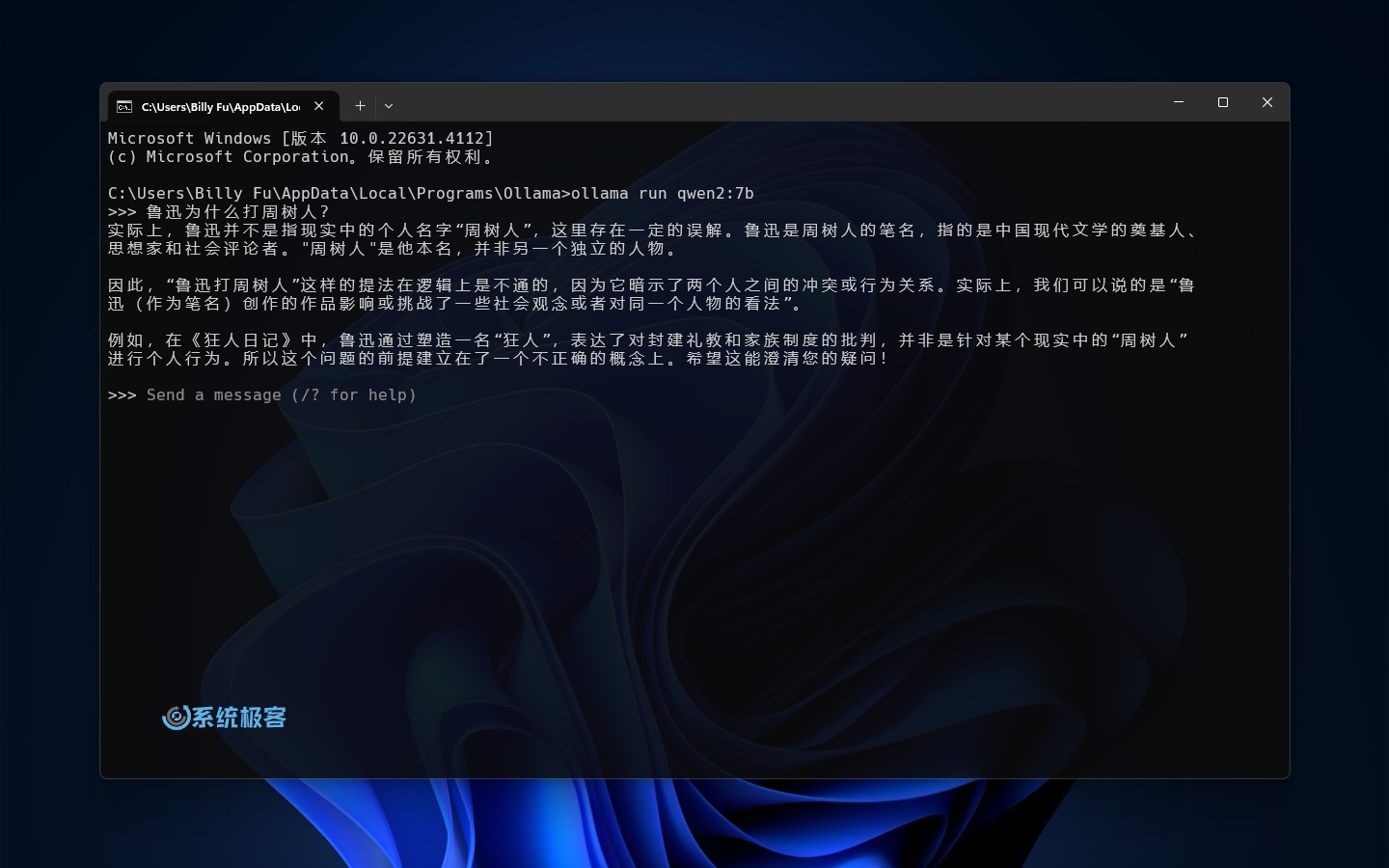
- 文本模型:文本模型是最常见的 AI 模型类型,可以用于对话、问答、文本生成等任务。例如,使用阿里的 Qwen2 模型:
ollama run qwen2:7b
- 图像模型:图像模型可以分析和理解图片内容,非常适合图像识别、物体检测等任务。例如,使用 LLaVA 模型对图片进行分析,并根据你的问题给出相应的结果。
ollama run llava:7b
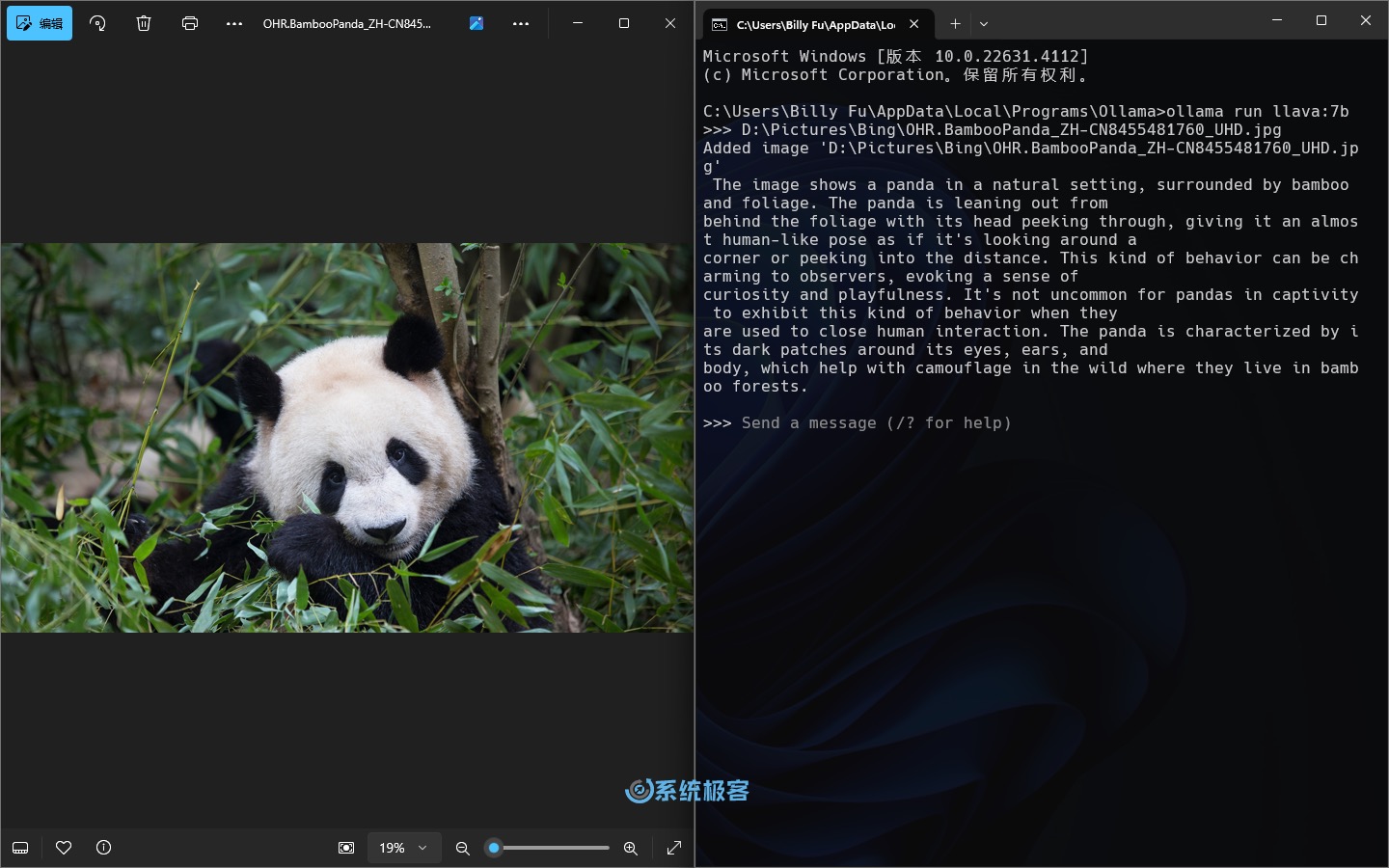
3.3 连接到 Ollama API
如前所述,Ollama 不仅可以在命令行中使用,还提供了强大的 API 接口,它兼容 OpenAI 的 Chat Completions API,让你能够在各种应用和程序中调用 AI 模型。
- 你可以在 OpenAI Translator、NextChat 和 LoboChat 等应用中直接调用 Ollama API。
- 如果你是开发者,可以在自己的应用中通过 HTTP 请求调用 Ollama API。
以下是使用cURL命令调用 Phi-3-medium 模型(OpenAI 兼容 API 端点)的示例:
curl http://192.168.100.6:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "phi3:medium-128k",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "天空为什么是蓝色的?"
}
]
}'
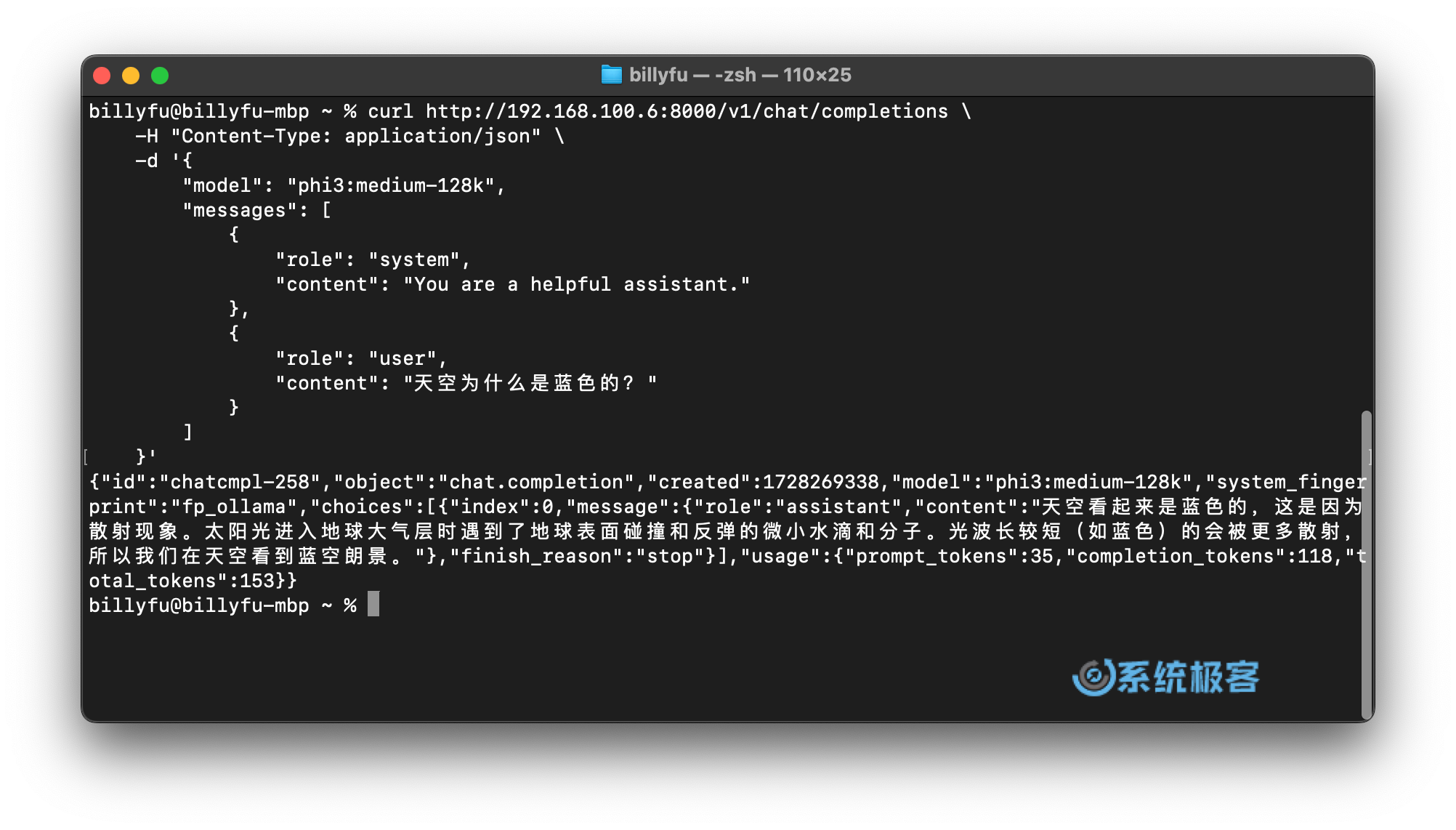
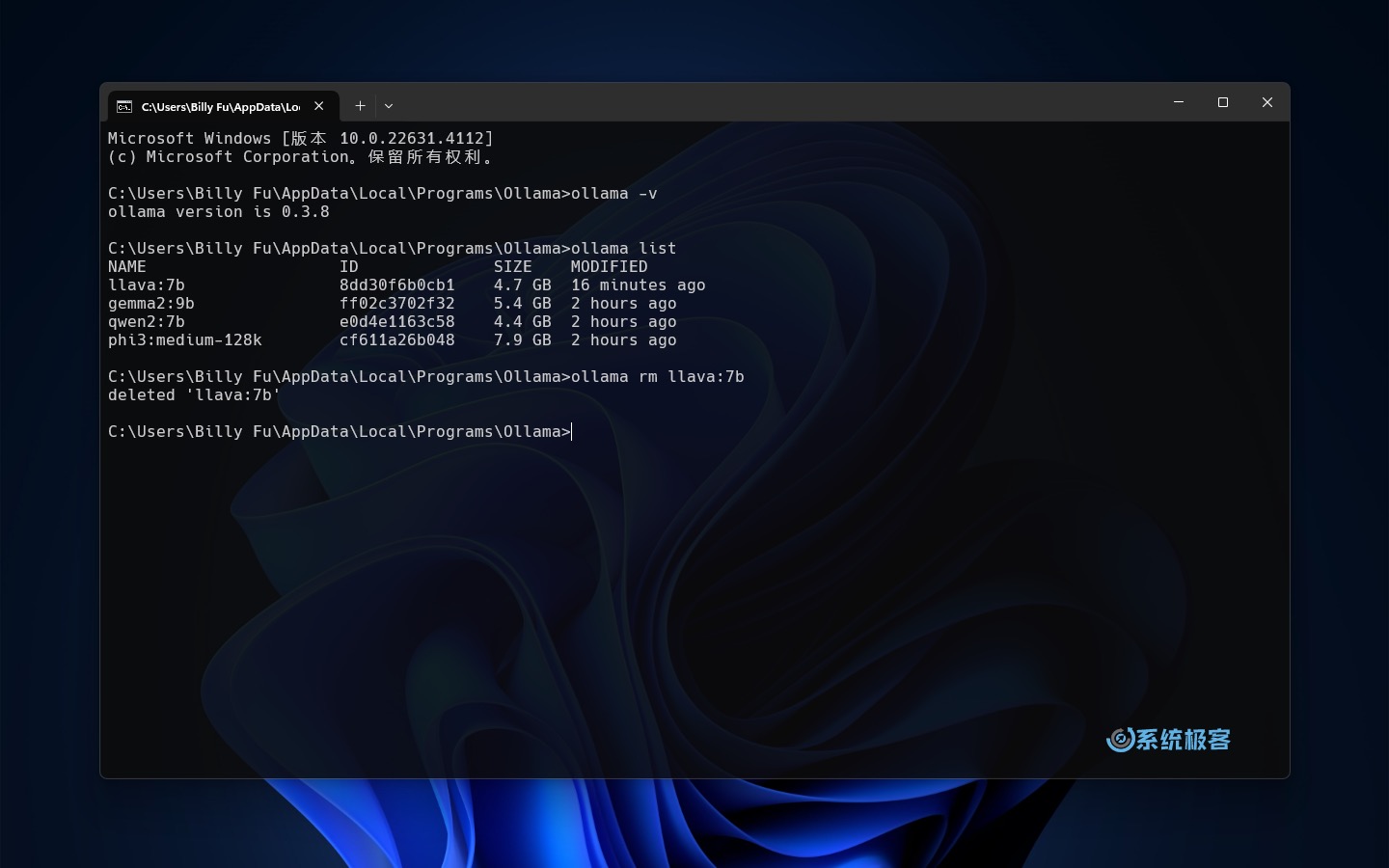
Ollama 常用命令
| 命令 | 说明 |
|---|---|
ollama -v | 查看 Ollama 版本 |
ollama list | 查看已安装的模型 |
ollama rm <模型名称> | 删除指定模型 |
Ollama on Windows 最佳实践
要充分发挥 Ollama 在 Windows 上的潜力,需要注意以下最佳实践和技巧。这些建议将帮助你优化性能并解决常见问题:
优化 Ollama 性能
- 检查硬件配置:确保设备满足 Ollama 推荐的硬件要求,尤其是运行较大型模型时。如果你有 NVIDIA 或 AMD GPU,还可以享受 Ollama 提供的自动硬件加速,大幅提升计算速度。
- 更新驱动程序:保持显卡驱动程序是最新版本,确保与 Ollama 的兼容性和最佳性能。
- 释放系统资源:在运行较大型模型或执行复杂任务前,关闭不必要的程序,释放系统资源。
- 选择合适模型:根据任务需求选择适当的模型。大参数模型虽然可能更准确,但对算力的要求也更高。对于简单任务,使用小参数模型更有效率。
Ollama 常见问题解答
Ollama 有什么硬件要求?
要顺利运行 Ollama,你的系统必须具备运行 AI 模型的能力:
- 首先,你需要配备一个 GPU 来执行程序。使用 CPU 或集成 GPU 也不是不行,但将会非常缓慢,因此不推荐使用这种方式。
- 你的系统应装备一块至少具有 5 级算力的 Nvidia 或 AMD GPU。一些主流且兼容 Ollama 的 GPU 型号包括:
- NVIDIA RTX 40 系列、NVIDIA RTX 30 系列、GTX 1650 Ti、GTX 750 Ti 和 GTX 750
- AMD Vega 64、AMD Radeon RX 6000 系列 和 AMD Radeon RX 7000 系列
你可以在 Ollama 的官方文档中找到所支持 GPU 的完整列表。
Ollama 支持 NPU 或 TPU 吗?
目前,Ollama 并不支持 TPU 或 NPU,它需要的是 GPU。
可以纯 CPU 跑 Ollama 吗?
技术上可行,但并不推荐。Ollama 主要设计与 Nvidia 或 AMD 的 GPU 搭配使用,如果只用 CPU 运行 Ollama,性能会远幅低于预期水平。
在本指南中,我们学习了如何在 Windows 上安装、配置和使用 Ollama,还包括了执行基础命令、使用 Ollama 模型库,以及通过 API 调用 Ollama。建议你深入研究 Ollama,并尝试各种不同的模型。Ollama 的潜力无限,借助它,你可以实现更多有意思的可能!


最新评论
26100 IoT为什么LTSC好几个版本的补丁都是安装不上
我推荐使用GXDE系统,内有火星应用商店。
服务器应该没有“滚动更新”的需求吧,不过Canonical 倒是方便我们这些爱好者折腾了
不行 还是不允许